Calculating the frequency of words and word combinations allows for a detailed analysis of the examined material when combined with other functions of MAXQDA. MAXDictio offers its users three similarly-working functions:
- Frequency of words (in general)
- Frequency of words listed in the dictionary
- Frequency of word combinations
Since these functions have a similar layout as well, we are going to discuss them altogether at this point.
Whether you‘d like to analyze the frequency of words or word combinations, you will always come across the dialog option window first. The top half of the windows work the same in each function.
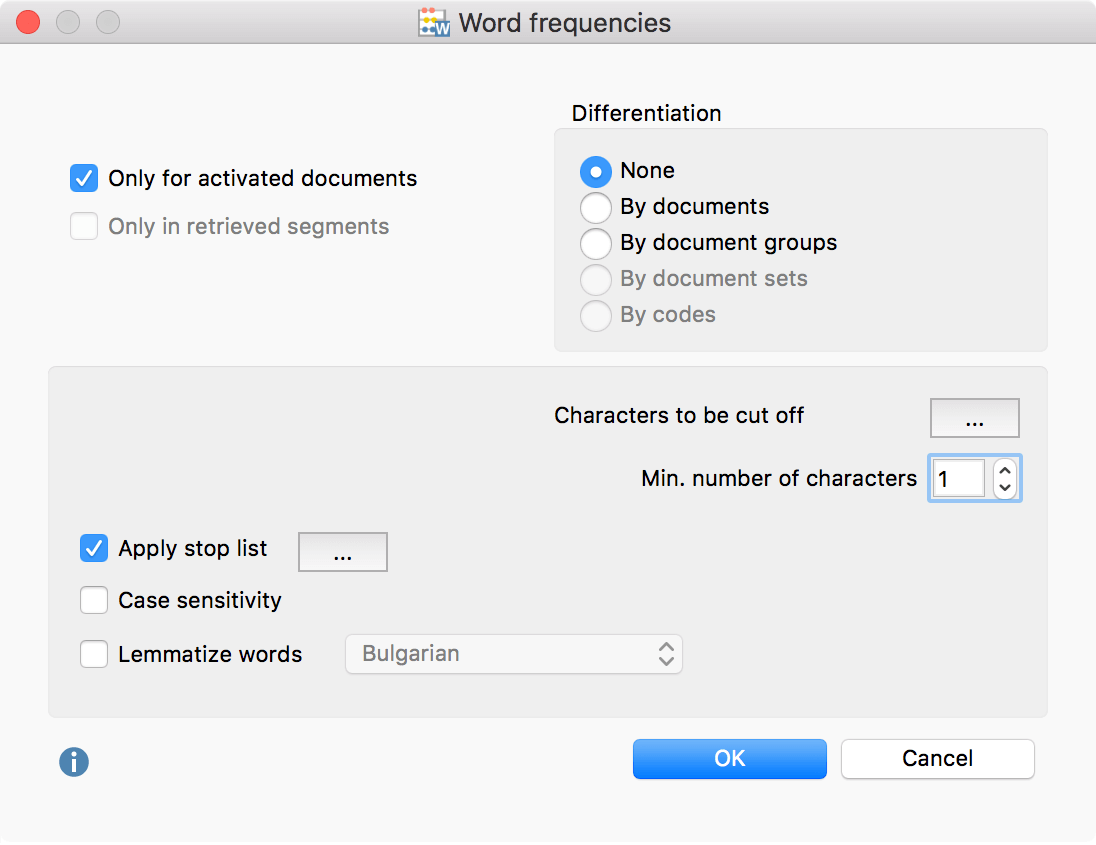
Listed on the left-hand side are the options for selecting the material. This could be all documents, only the activated documents, or the entries listed in the window ”list of codings“.
The option on the right-hand side allows for displaying additional columns, which can sort words by documents, set of documents, or codes.
The bottom of the window offers another two important options: the use of a stop-list, which filters every word on the list from calculating frequencies (Tip: Download prepared stop lists that you can use for your project) and the option to lemmatize words, which simplifies words to their word stem by using a lemma lexicon in the chosen language. So if the text contains the words “gave”, “given” or “gives”, it will list and count the base form “give” only.
Note: Acknowledge licence terms
MAXDictio uses lemmatize lists for this function that have been published under the Creative Commons and the Open Database License. If you use this function for a publication you have to give appropriate credit in a short note like the following:
Lemma list for German:
“A lemma list has been used that is based on “Deutsche Morphologie-Daten” by Daniel Naber (http://www.danielnaber.de/morphologie/), which is made available under the Creative Commons Attribution-ShareAlike 4.0 license (http://creativecommons.org/licenses/by-sa/4.0/).”
Lemma list for other languages:
“A lemma list has been used that was originally provided by Michal Boleslav Měchura (http://www.lexiconista.com/datasets/lemmatization/), which is made available under the Open Database License (ODbL) (http://opendatacommons.org/licenses/odbl/1.0/).”
Now let us have a look at the result window:
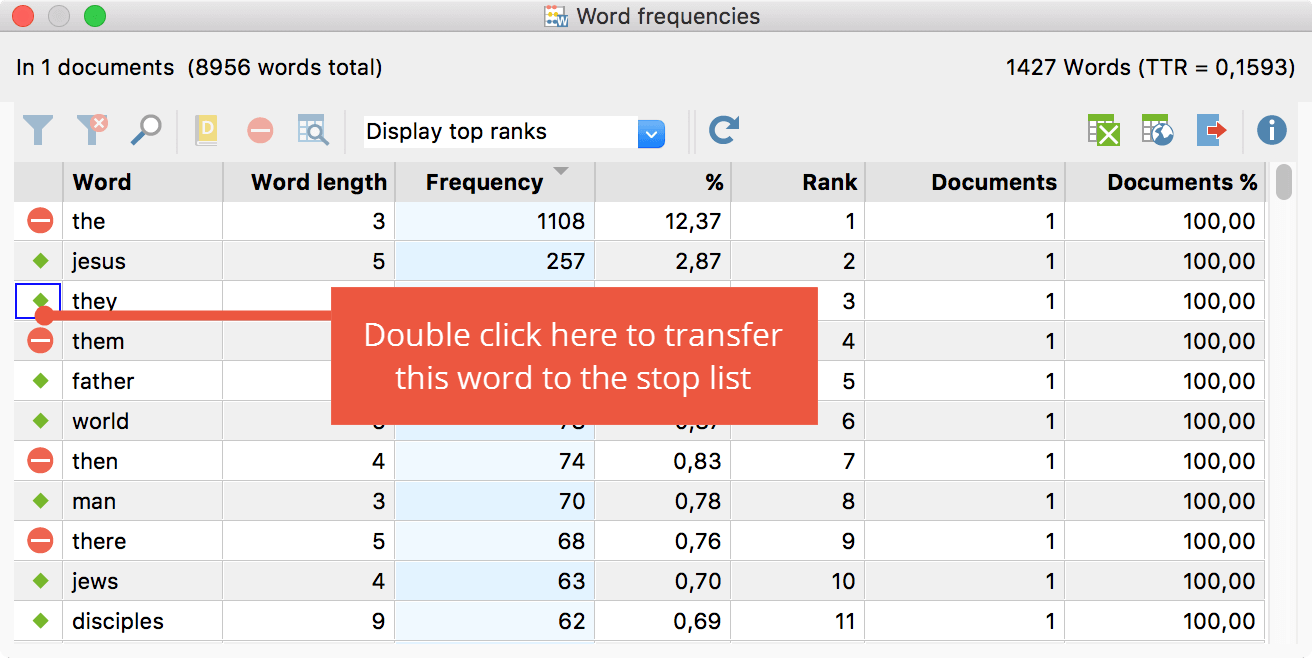
The columns display the words or word combinations, their length or the number of words per combination, the absolute and the relative appearance in the examined documents, and the number of examined documents in which the word (or word combination) can be found. The two additional columns to the right display information about the group of documents in this case.
By clicking on one of the blue buttons in the middle you can switch between the display of frequencies, ranks and distribution of documents for each column. The button to the left allows for setting the maximum amount of ranks. If you would like to reduce the amount of words to 10, as shown in the following illustration, then the ranks for the additional columns will also only be calculated for the 10 most frequent words.
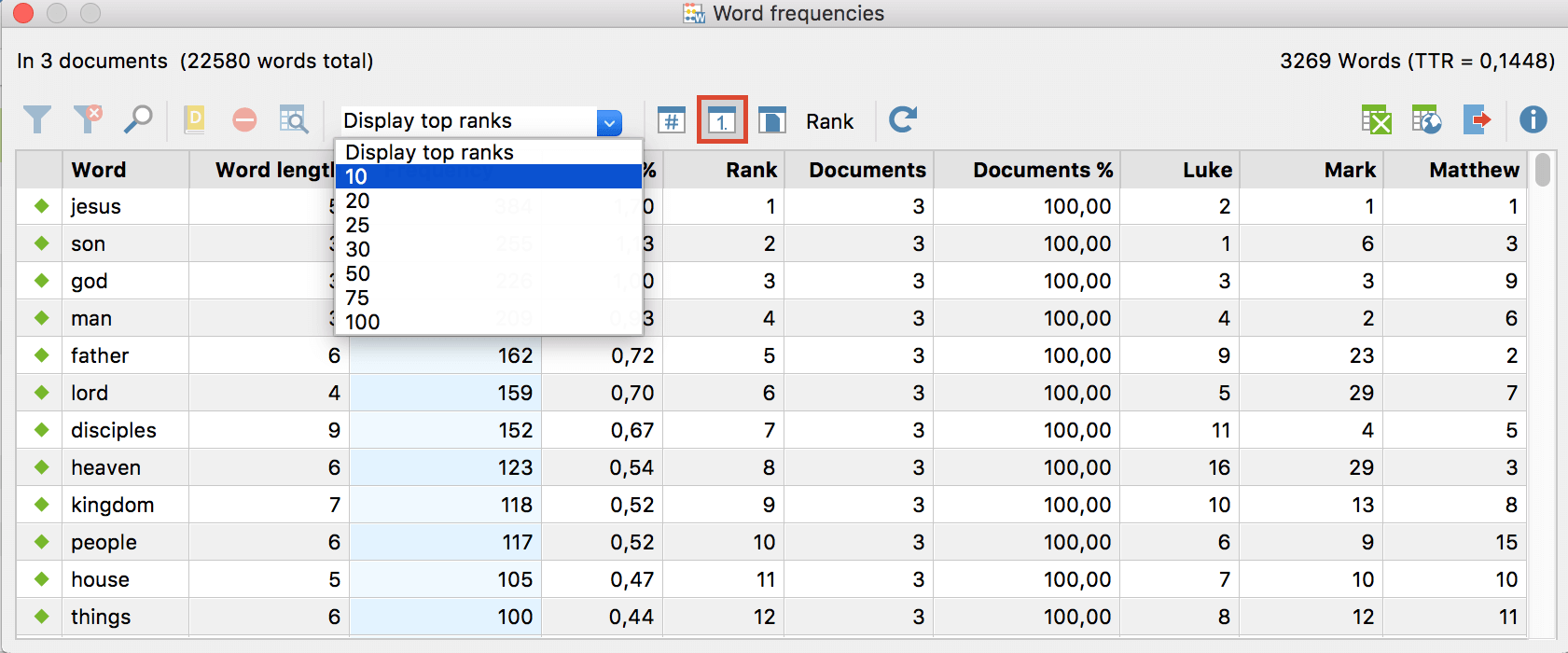
You can filter your results by right-clicking on one of the columns, which then displays only word combinations with certain words, or only words which can be found in more than 75% of all documents. Alternatively, you can use the search function.
By right-clicking on an entry you can transfer it to the stop-list. This can also be done by double-clicking the green point in the first column, or by selecting one or more entries by pressing the STRG or SHIFT button, and then excluding them by clicking on the button in the menu bar. These entries will be gone after clicking on the refresh button.
Additionally, it is also possible to display the position of the search results.