Für die Zuordnung von Codes zu qualitativem Datenmaterial sollten bestimmte Qualitätskriterien angelegt werden. Selbstverständlich erwartet man, dass die Zuordnung nicht arbiträr und willkürlich passiert, sondern so geschieht, dass ein möglichst hoher Grad von Übereinstimmung zwischen Codierenden erreicht wird. Die MAXQDA-Funktion „Intercoder-Übereinstimmung“ ermöglicht es, die Codierungen von zwei unabhängig voneinander codierenden Personen miteinander zu vergleichen. Da es in der qualitativen Forschung eher darauf ankommt, die Übereinstimmung zu verbessern und gemeinsam zu diskutieren, wo man bei Codierungen Differenzen hat und zu klären, warum diese Differenzen bestehen, wurde bei der Konzipierung der Funktion „Intercoder-Übereinstimmung“ besonderes Augenmerk auf den Prozess der Codierung und die Bearbeitung von Codiererdifferenzen gelegt, während die bloße Berechnung eines Übereinstimmungsmaßes nur eine untergeordnete Bedeutung besitzt. Gleichwohl wird natürlich auch eine solche Maßzahl für die Übereinstimmung von zwei Codierern berechnet.
Bei der qualitativen Analyse strebt man an, eine möglichst hohe Zuverlässigkeit der Codezuordnungen zu erreichen. Anders als in üblichen Messungen der Reliabilität in der quantitativ orientierten Forschung geht es also nicht um die Ermittlung eines Koeffizienten, der die Güte gewissermaßen statisch angibt, sondern es geht primär um eine praktische Verbesserung der Güte der Codierungen. Man bleibt also nicht bei der Ermittlung eines Koeffizienten stehen, sondern will die Unstimmigkeiten von Codierenden beseitigen, so dass man mit „besser“ codiertem Material weiterarbeiten kann.
Ablauf der Intercoder-Übereinstimmung
Die Funktion zur Überprüfung der Intercoder-Übereinstimmung verlangt folgendes Procedere:
- Zwei Codierende bearbeiten das identische Dokument unabhängig voneinander und codieren es entsprechend den gemeinsam vereinbarten Code-Definitionen. Dies kann am gleichen Computer oder auch auf entfernten Computern erfolgen. Wichtig ist natürlich, dass beide Personen nicht einsehen können, was die andere codiert hat.
- Verwenden Sie die integrierten Funktionen von MAXQDA (z. B. Start > Projekt aus aktivierten Dokumenten), um Dokumente an die Codierenden zu verteilen – importieren Sie dieselbe Quelldatei nicht mehrfach oder auf verschiedenen Betriebssystemen.
- Bearbeiten Sie ein Dokument nicht mehr, nachdem Sie es an die Codierenden verteilt haben.
- Um zu überprüfen, ob zwei Dokumente identisch sind, vergleichen Sie ihre Zeichenanzahl: Öffnen Sie Variablen > Datentabelle der Dokumentvariablen und vergleichen Sie den Wert „Zeichen" für beide Dokumente. Die Werte müssen exakt übereinstimmen.
- Zur Überprüfung müssen sich die beiden von unterschiedlichen Personen codierten Dokumente im gleichen MAXQDA-Projekt befinden. Die Dokumente müssen identisch heißen, sich aber in unterschiedlichen Dokumentgruppen befinden!
Um dieses Procedere umzusetzen, bietet sich folgender Ablauf an:
- Stellen Sie sicher, dass alle Dokumente, die von einer zweiten Person codiert werden sollen, einer Dokumentgruppe zugeordnet sind (und nicht auf der obersten Ebene liegen).
- Aktivieren Sie alle Dokumente, die von einer zweiten Person codiert werden sollen. Erzeugen Sie mit Start > Projekt aus aktivierten Dokumenten eine Projektkopie, welche nur die zuvor aktivierten Dokumente enthält.
- Geben Sie diese Projektkopie an die zweite Person weiter.
- Beide Personen schreiben hinter alle Dokumentgruppen ihren Namen.
- Beide Personen codieren unabhängig voneinander das Datenmaterial, fügen ggf. neue Codes hinzu (es empfiehlt sich, neuen Codes eine zuvor vereinbarte Farbe zuzuweisen, um diese leicht erkennen zu können).
- Nutzen Sie die Funktion Start > Projekte zusammenführen, um beide Projekte in eins zu fusionieren. Die „Liste der Dokumente“ enthält dann die entsprechenden Dokumente zweimal – einmal codiert von Person 1 und einmal codiert von Person – und sieht dann beispielsweise so aus:

- Jetzt lässt sich die Intercoder-Funktion von MAXQDA anwenden, um die Codierungen zu vergleichen.
- Nach Abschluss des Vergleichs können die hinzugefügten Dokumente von Person 2 gelöscht werden.
Start der Intercoder-Übereinstimmung
Über Analyse > Intercoder-Übereinstimmung kann die Überprüfung gestartet werden.

Es erscheint der folgende Dialog, in dem Sie die Einstellungen für die Prüfung der Intercoder-Übereinstimmung vornehmen können.

- Wählen Sie im oberen Aufklapp-Menü die Dokumentgruppe oder das Dokumentset mit den Dokumenten von Person 1 und im unteren von Person 2.
- Sie können die Analyse durch Wahl Anklicken der entsprechenden Optionen auf die derzeit aktivierten Dokumente und/oder Codes einschränken.
- Im unteren Bereich lässt sich zwischen drei alternativen Analysestufen der Intercoder-Übereinstimmung wählen:
- Vorhandensein des Codes im Dokument – Pro Dokument wird überprüft, ob beide Personen die gleichen Codes zugeordnet haben.
- Häufigkeit des Codes im Dokument – Pro Dokument wird überprüft, ob beide Personen die gleichen Codes gleich häufig zugeordnet haben.
- Codeüberlappung an Segmenten – Pro Codierung wird überprüft, ob die jeweils andere Person dem Segment den gleichen Code zugeordnet hat.
Im Folgenden sind alle drei Varianten und die jeweilige Ergebnisdarstellung im Detail erläutert.
Variante 1 (Vergleichslevel Dokument): Vorhandensein des Codes im Dokument
Pro Dokument wird überprüft, ob beide Personen die gleichen Codes zugeordnet haben. Vergleichskriterium ist also die Präsenz bzw. die Nicht-Präsenz des Codes im Dokument. Diese Option ist beispielsweise interessant, wenn man relativ kurze Dokumente wie etwa Freitextantworten eines Surveys bearbeitet und mit vielen Codes arbeitet.
MAXQDA gibt zwei Tabellen aus, die „Codespezifische Ergebnistabelle“ mit den ausgewerteten Codes und die „Ergebnistabelle“ mit Detailinformationen zu jedem verglichenen Dokument.
Die codespezifische Ergebnistabelle
Die codespezifische Ergebnistabelle listet alle ausgewerteten Codes auf und zeigt für jeden Code an, bei wie viel Dokumenten die Codierenden übereinstimmen:

Die Beispieltabelle zeigt oben rechts, dass insgesamt 6 Codes ausgewertet wurden. Nur beim Code „Ressourcenknappheit …“ gab es Uneinigkeit, und zwar bei zwei Dokumenten, wie in der Spalte „Nicht-Übereinstimmung“ durch die Zahl 2 angegeben ist (die Zahlen in den Spalten „Übereinstimmung“, „Nicht-Übereinstimmung“ und „Gesamt“ beziehen sich auf die Anzahl an Dokumenten).
Die Spalte „Prozentual“ gibt an, wie hoch die prozentuale Übereinstimmung bei dem jeweiligen Code ist. Die Zeile Total wird für die Berechnung der mittleren prozentualen Übereinstimmung verwendet – im Beispiel beträgt sie 90,00 %.
Die detaillierte Ergebnistabelle mit ausgewerteten Dokumenten
Die Ergebnistabelle listet alle ausgewerteten Dokumente auf und liefert dadurch detaillierte Informationen über die Übereinstimmung bei einzelnen Dokumenten.

Die Tabelle hat folgenden Aufbau:
- Die erste Spalte zeigt ein grünes Symbol, wenn Person 1 und 2 dem Dokument die gleichen Codes zugewiesen haben. In diesem Fall gibt es zwei „Nicht-Übereinstimmungen“ bei 6 Dokumenten, symbolisiert durch rote Symbole.
- Die Spalte „Übereinstimmung“ zeigt die Anzahl an Codes, die bei diesem Dokument zwischen Codierer 1 und Codierer 2 übereinstimmen.
- Die Spalte „Prozentual“ gibt die prozentuale Übereinstimmung (also die relative Anzahl übereinstimmender Codes) wieder. Die prozentuale Übereinstimmung errechnet sich wie folgt: Übereinstimmungen / (Übereinstimmungen + Nicht-Übereinstimmungen). Für Interview 2 ergibt sich im Beispiel ein Wert von 6 / (6+1) Codes = 85,71 % – so hoch ist der Anteil an Codes, die bei Interview 2 übereinstimmen.
- Die letzte Spalte gibt einen Kappa-Wert an, der eine Zufallskorrektur für die Übereinstimmung enthält (Berechnung: siehe unten).
- Die letzte Zeile „<Total>“ summiert die Übereinstimmungen und Nicht-Übereinstimmungen auf. Die Zahl in der Spalte „Prozentual“ entspricht der durchschnittlichen Anzahl an übereinstimmenden Codes, im Beispiel sind es 95,24 Prozent.
Die Kopfzeile enthält weitere Informationen:
- Linksseitig sehen Sie die Anzahl der vorgenommenen Codierungen der beiden Personen, was häufig schon erste Hinweise auf gleiches oder unterschiedliches Codierverhalten geben kann. Im Beispiel hat die eine Person 24 Segmente und die andere 28 codiert.
- Rechtsseitig steht die Anzahl der ausgewerteten Dokumente sowie die relative Anzahl identisch codierter Dokumente: Dies sind im Beispiel 4 von 6 Dokumenten, entsprechend 66,67 %.
Die Symbolleiste enthält neben den MAXQDA-üblichen Funktionen zum Neuaufrufen der Funktion sowie zum Filtern und Exportieren, folgende wichtige Funktionen:
![]() Nur Nicht-Übereinstimmungen anzeigen – Blendet alle Zeilen mit Übereinstimmungen aus und ermöglicht den schnellen Zugriff auf Dokumente, bei denen Codierende nicht übereinstimmen.
Nur Nicht-Übereinstimmungen anzeigen – Blendet alle Zeilen mit Übereinstimmungen aus und ermöglicht den schnellen Zugriff auf Dokumente, bei denen Codierende nicht übereinstimmen.
Nicht vergebene Codes ignorieren / als Übereinstimmung werten – Hier entscheiden Sie, ob ausgewertete Codes, die von beiden Codierenden nicht vergeben wurden, als Übereinstimmung gelten sollen oder ignoriert werden sollen. Anhand folgender Tabelle wird der Unterschied erläutert:
| Codierer 1 | Codierer 2 | Übereinstimmung? | |
|---|---|---|---|
| Code A | X | X | ja, immer |
| Code B | X | nein, niemals | |
| Code C | je nach gewählter Option |
Code C wurde in die Prüfung der Intercoder-Übereinstimmung mit einbezogen, doch wurde er weder von Person 1 noch von Person 2 im Dokument vergeben. Wählen Sie hier die Option Nicht vergebene Codes ignorieren, wird der Code C ignoriert und die relative Anzahl übereinstimmender Codes beträgt 1 von 2 = 50 %. Bei Wahl der anderen Option beträgt die Übereinstimmung 2 von 3 = 67 %, denn hierbei wird Code C berücksichtigt.
Interaktivität der Ergebnistabelle
Die Ergebnistabelle ist interaktiv. Ein Doppelklick auf eine Zeile öffnet den Code-Matrix-Browser für das zugehörige Dokument:

In der Titelleiste steht das verglichene Dokument, im Beispiel „Interview 3“. Die Ansicht zeigt sofort, wo sich die beiden Codierenden uneinig waren: Person 1 hat den Code „Ressourcenknappheit …“ vergeben, Person 2 jedoch nicht.
Berechnung von Kappa (Rädiker & Kuckartz)
In der Spalte „Kappa (RK)“ gibt die Ergebnistabelle einen zufallskorrigierten Wert für die prozentuale Übereinstimmung an. Dabei wird berücksichtigt, mit welcher Wahrscheinlichkeit zwei Personen zufällig die gleichen Codes in einem Dokument auswählen (wenn sie einfach Codes zufällig auswählen würden, ohne das Datenmaterial zu berücksichtigen). Die Berechnung hat nur bei gewählter Option Nicht vergebenen Codes als Übereinstimmung Sinn und ist deshalb nur bei dieser Wahl sichtbar.
Kappa (Rädiker & Kuckartz), abgekürzt Kappa (RK), berechnet sich wie folgt:
Ac = Agreement by chance = 0,5 hoch Anzahl der für die Analyse ausgewählten Codes
Ao = Agreement observed = prozentuale Übereinstimmung
Kappa (RK) = (Ao – Ac) / (1 – Ac)
Die Zufallskorrektur fällt generell sehr gering aus, weil die Wahrscheinlichkeit für die zufällige Übereinstimmung mit zunehmender Anzahl an Codes sehr schnell vernachlässigbar klein wird. Daher ist es nur sinnvoll, diese Korrektur zu verwenden, wenn Sie maximal 3 Codes in die Intercoderprüfung einbeziehen.
Variante 2 (Vergleichslevel Dokument): Häufigkeit des Codes im Dokument
Bei dieser Analysevariante gilt als Übereinstimmung, wenn zwei Codierende einen Code gleich häufig im Dokument vergeben haben. Die Differenz der Häufigkeiten spielt keine Rolle: Ob eine Person einen Code A einmal und die andere dreimal oder ob die Differenz einmal vs. sechsmal beträgt, wird immer als eine Nicht-Übereinstimmung gewertet.
Das Ergebnis für diese zweite Analysevariante entspricht vom Prinzip her der ersten Variante mit folgenden Ausnahmen:
- Codespezifische Tabelle: Die Spalte "Übereinstimmung" informiert über die Anzahl der Dokumente, bei denen die Häufigkeiten pro Code zwischen den Personen übereinstimmen, und die Spalte "Abweichung" informiert über die Anzahl der Dokumente, bei denen die Codehäufigkeiten voneinander abweichen.
- Ergebnistabelle mit ausgewerteten Dokumenten:
- In den Zellen steht, wie viele Codes gleich häufig von beiden Codierenden im Dokument vergeben wurden.
- Die Spalte „Kappa (RK)“ wird niemals angezeigt.
- Ein Doppelklick auf eine Zeile zeigt ebenfalls den Code-Matrix-Browser an, hier zeigen unterschiedlich große Quadrate jetzt Unterschiede im Codierverhalten beim angeklickten Dokument an.
Variante 3 (Vergleichslevel Segment): Codeüberlappung an Segmenten von mindestens X%
Es wird geprüft, ob die beiden Personen beo der Codierung einzelner Segmente übereinstimmen. Diese Variante ist die am weitesten gehende und für qualitative Codierung typische Variante.
Da Texte bei qualitativen Auswertungsverfahren häufig nicht in fixierte Texteinheiten untergliedert werden, erfolgt die Prüfung der Übereinstimmung standardmäßig für jedes von den beiden Personen codierte Segment (im Dialog ist eingestellt Auswerten: Segmente beider Personen). Es wird also für jedes codierte Segment evaluiert, ob eine Übereinstimmung vorliegt. Hat Person 1 bspw. 12 Segmente codiert und Person 2 hat 14 codiert, so werden 26 Prüfvorgänge durchgeführt und die später ausgegebene Detailtabelle besitzt 26 Zeilen.
Alternativ lässt sich auswählen, dass man nur die Segmente von Person 1 oder die Segmente von Person 2 auswerten möchte. Dies kann beispielsweise hilfreich sein, um zu testen, inwieweit eine Person mit einer Referenzcodierung übereinstimmt.
Toleranz bei den Segmentgrenzen einstellen
Häufig ist es so, dass Codierende bei der Zuordnung von Codes minimal voneinander abweichen, z.B. weil die eine Person ein Wort mehr oder weniger codiert hat. Dies ist inhaltlich meist irrelevant, kann aber bei Forderung einer absolut identischen Codierung zu einer unnötig kleinen prozentualen Übereinstimmung und „falschen“ Nicht-Übereinstimmungen, gewissermaßen „Fehlmeldungen“, führen.
Daher können Sie im Optionsdialog vorab festlegen, wann zwei Codierungen als übereinstimmend gewertet werden sollen. Als Kriterium wird der prozentuale Anteil des überlappenden Bereichs zweier Codierungen herangezogen. Dieser Anteil entspricht dem Überschneidungsbereich zweier Codierungen im Verhältnis zum Gesamtbereich, den die beiden Codierungen mit ihren äußersten Segmentgrenzen abdecken:
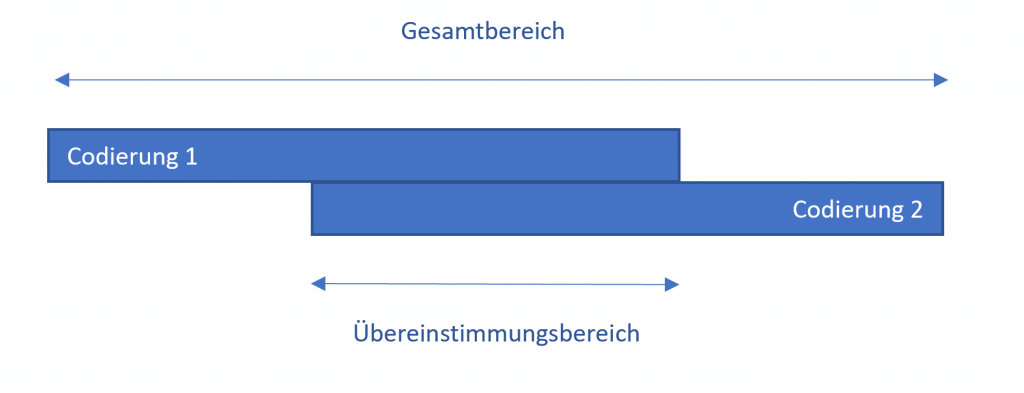
Die Eingabe erfolgt in Prozent und der Schwellenwert kann im Dialogfenster eingestellt werden. Der Standardwert beträgt 90%, kann aber testweise höher einstellt und bei zu vielen „Falschmeldungen“ dann Schritt für Schritt reduziert werden.
Es werden zwei Ergebnistabellen ausgegeben: die codespezifische Ergebnistabelle und die segmentspezifische Tabelle.
Die codespezifische Ergebnistabelle

Diese Tabelle besitzt so viele Zeilen, wie Codes in die Übereinstimmungsüberprüfung einbezogen wurden. Codes, die von keinem der beiden Codierenden vergeben wurden, werden nicht in die Tabelle aufgenommen, auch wenn sie für die Analyse ausgewählt wurden. Die Tabelle gibt einen Überblick über die Übereinstimmungen und Nicht-Übereinstimmungen der beiden Codierenden. Sie zeigt an, wo die Schwachstellen sind, d.h. bei welchen Codes der angestrebte prozentuale Grad an Übereinstimmung nicht erreicht wird.
Für jeden Code ist angegeben, wie viele Segmente insgesamt codiert wurden (Spalte „Gesamt“), wie groß die Zahl der Übereinstimmungen ist und wie hoch der codespezifische Übereinstimmungs-Prozentsatz ist. In der Zeile <Total> werden die (Nicht-)Übereinstimmungen addiert, sodass eine durchschnittliche prozentuale Übereinstimmung berechnet werden kann.
Die detaillierte Ergebnistabelle mit den ausgewerteten Segmenten
Die zweite Tabelle ermöglicht die genaue Inspektion, man kann also ermitteln, bei welchen codierten Segmenten die beiden Codierenden nicht übereinstimmen. Die Tabelle enthält je nach gewählter Einstellung die Segmente beider Personen oder nur die Segmente einer Person und zeigt jeweils an, ob die zweite Person an dieser Stelle den gleichen Code vergeben hat:

Eine Übereinstimmung erkennen Sie direkt am grünen Symbol in der ersten Spalte. Ein rotes Icon in dieser Spalte zeigt hingegen an, dass es bei diesem Segment keine Übereinstimmung gibt.
Interaktivität der Ergebnistabelle: Segmente vergleichen
Die Ergebnistabelle ist interaktiv mit den Originaldaten verbunden und erlaubt das gezielte Inspizieren der analysierten Segmente:
- Ein Klick auf eine Zeile markiert beide zugehörigen Dokumente in der „Liste der Dokumente“ und öffnet sie standardmäßig in eigenen Tabs, wobei das angeklickte Segment hervorgehoben wird. In der Symbolleiste können Sie die Einstellung wechseln von In zwei Tabs anzeigen zu In zwei Dokument-Browsern anzeigen, dann wir das Dokument von „Codierer 2“ in einem eigenen Fenster angezeigt. Diese Option ist besonders praktisch, wenn Sie mit zwei Bildschirmen arbeiten.
- Ein Doppelklick auf das kleine Quadrat in der Spalte „Person 1“ bzw. „Person 2“ fokussiert das zugehörige Dokument im „Dokument-Browser“ an genau der Position des fraglichen Segmentes. So kann man leicht zwischen den beiden Dokumenten hin und her springen und beurteilen, welcher der beiden Codierer denn nun den Code entsprechend der Zuordnungsvorschrift angewandt hat.
- Klicken Sie mit der rechten Maustaste auf eine Zeile, erscheint wie im Bild oben zu sehen ein Kontextmenü, das es erlaubt die Codierung bzw. Nicht-Codierung aus dem einen Dokument in das andere direkt zu übertragen. Wählen Sie hierzu beispielsweise die Option Übernehme Lösung von Person 1.
Koeffizient Kappa für die segmentgenaue Übereinstimmung
Wenngleich die Analyse der Intercoder-Übereinstimmung in der qualitativen Forschung meist primär zur Verbesserung von Codieranweisungen und einzelnen Codierungen dient, besteht dennoch häufig der Wunsch auch prozentuale Übereinstimmungen von Codierern zu berechnen – insbesondere mit Blick auf den späteren Forschungsbericht. Diese prozentualen Übereinstimmungen finden sich in der oben vorgestellten codespezifischen Ergebnistabelle von MAXQDA für jeden einzelnen Code und für alle Codes zusammen betrachtet.
Forschende äußern häufig zusätzlich den Wunsch, in ihren Ergebnisberichten nicht nur die prozentualen Übereinstimmungsraten berichten zu können, sondern auch zufallsbereinigte Koeffizienten auszuweisen. Die Grundidee derartiger Koeffizienten besteht darin, die prozentuale Übereinstimmung um den Anteil zu reduzieren, den man bei einer zufälligen Zuordnung von Codes zu Segmenten erhalten würde.
In MAXQDA lässt sich für diesen Zweck der häufig verwendete Koeffizient „Kappa (nach Brennan & Prediger, 1981)“ berechnen: Klicken Sie in der Ergebnistabelle auf das K-Symbol für Kappa, um die Berechnung für die aktuell durchgeführte Analyse zu starten. MAXQDA zeigt Ihnen daraufhin folgendes Ergebnisfenster:
")
In der linken oberen Ecke der Vierfelder-Tafel steht die Anzahl der Codierungen, die übereinstimmen. In der rechten oberen Ecke und der linken unteren Ecke finden sich die Nicht-Übereinstimmungen, bei denen also in einem Dokument ein Code vergeben wurde, aber nicht in dem anderen. Da in MAXQDA bei der Intercoder-Übereinstimmung auf Segmentebene nur die Segmente berücksichtigt werden, bei denen mindestens ein Code vergeben wurde, ist die Zelle unten rechts per definitionem gleich Null (denn es werden ja keine Dokumentstellen in die Analyse einbezogen, die von beiden Codierern nicht codiert wurden).
“P(observed)” entspricht der einfachen prozentualen Übereinstimmung, wie sie in der Zeile “TOTAL” der codespezifischen Ergebnistabelle bereits ausgegeben wurde.
Für die Bestimmung von “P (chance)”, der zufälligen Übereinstimmung, greift MAXQDA auf einen Vorschlag von Brennan und Prediger (1981) zurück, die sich intensiv mit optimalen Einsatzmöglichkeiten von Cohens Kappa und dessen Problemen bei ungleichen Randsummenverteilungen auseinandergesetzt haben. Bei dieser Berechnungsweise wird die zufällige Übereinstimmung anhand der Anzahl unterschiedlicher Kategorien bestimmt, die von beiden Codierenden benutzt wurden. Diese entspricht der Anzahl der Codes in der codespezifischen Ergebnistabelle.
Voraussetzungen für die Berechnung von zufallskorrigierten Koeffizienten wie Kappa
Eine Bedingung für die Berechnung von zufallskorrigierten Koeffizienten wie Kappa ist, dass vorab Segmente festgelegt werden, welche von den Codierenden mit einem Set an vorgegebenen Codes versehen werden. Häufig wird in der qualitativen Sozialforschung jedoch das Vorgehen praktiziert, dass eben keine Segmente a-priori definiert werden, sondern stattdessen beide Codierenden die Aufgabe haben, alle aus ihrer Sicht relevanten Dokumentstellen zu identifizieren und einen oder mehrere passende Codes zuzuordnen. In diesem Fall ist die Wahrscheinlichkeit, dass zwei Personen die gleiche Stelle mit dem gleichen Code codieren, noch geringer und folglich wäre Kappa noch größer. Man kann hier sogar argumentieren, dass die Wahrscheinlichkeit für zufällig auftretende Codier-Übereinstimmungen bei einem Text mit mehreren Seiten und mehreren Codes so verschwindend klein ist, dass Kappa der einfachen prozentualen Übereinstimmung entspricht. In jedem Fall sollte die Berechnung von Kappa gut überlegt sein.