Guest post by Ruijie Peng.
After being in the field for about eight months, I have now collected many kinds of data including dozens of interview transcripts, hundreds of pages of field notes, analytical memos and summary notes. Even with all the materials in hand, I still experience moments of stress about the question that bothers many field researchers: what if I haven’t collected enough material?
In the back of my mind, I tell myself that there is no official gold standard for judging whether the material you collect is ever truly “enough”. Nevertheless, I wanted to find out what else I should collect to enrich my case studies and what I have not paid enough attention to or ignored. So I began this phase of my work, starting by reading through my interview transcripts and field notes.

The Old-School Ethnographer and MAXQDA
As an “old-school” ethnographer, I wrote field notes with a notebook and fountain pen. I did this not because it made me feel any more “authentic”, but because writing on paper proved to be a better way for me to think more clearly about the ideas I wanted to express. I could also keep ample supplies of ink and paper with me to sustain the writing process, as opposed to devices that required electricity, which was not always available.
As you can imagine, the next step was to figure out how to transfer these handwritten notes into my MAXQDA project. I solved this issue by scanning my notes and converting them into PDF documents, which I could then code with MAXQDA. The program was equally capable of dealing with this type of document, but it required me to do more preparation work to regroup my notes according to the respective family before importing them into the project. For this type of document, it proved important to use codes to identify socio-demographic facts since I couldn’t search texts to locate these segments – but I could use codes to locate who did what in the coded segments.
Helpful MAXQDA Tools for Refining the Code System
In doing fieldwork, I often noticed the importance of emotions and how they might motivate my project’s research partners to make decisions and take actions. When I read through the interview transcripts, I found that many statements, and conversations in general, revolve around the participant’s feelings and emotional expressions. In the broad coding phase, I therefore roughly grouped these data segments under the code “Emotional experience”. I then waited to do the advanced rounds of detailed coding until I had gathered more observations and thoughts.
Using MAXMaps to break down big codes in interview transcripts
It then became important to tease out which kinds of emotions corresponded to which kinds of actions. The broad code “Emotional experience” had grown so much during the process of coding, that the task of breaking down the broad code into smaller and more specific ones, became a necessary next step. I used MAXQDA’s MAXMaps feature, found under the Visual Tools tab to make a space for exploring ideas and sketching narrower codes.
I opened MAXMaps and chose to work in the Single-Code Model. I then dragged the “Emotional experience” code from the “Code System” window into the map. This allowed me to see the coded segments under this code, move them around, and group them according to the emotion that I had identified.
This process was quite experimental and explorative, and it presented me with many possibilities and ways to interpret the data segments I had coded in the first round of coding. When subgroups started to take clearer shapes in my map, I inserted text boxes next to the group of codes and labeled them according to specific emotions such as “fear”, “worry and anxiety”, “regrets”, and so on. It helped me go through this close reading and thinking process without making real changes to the coding project just yet.
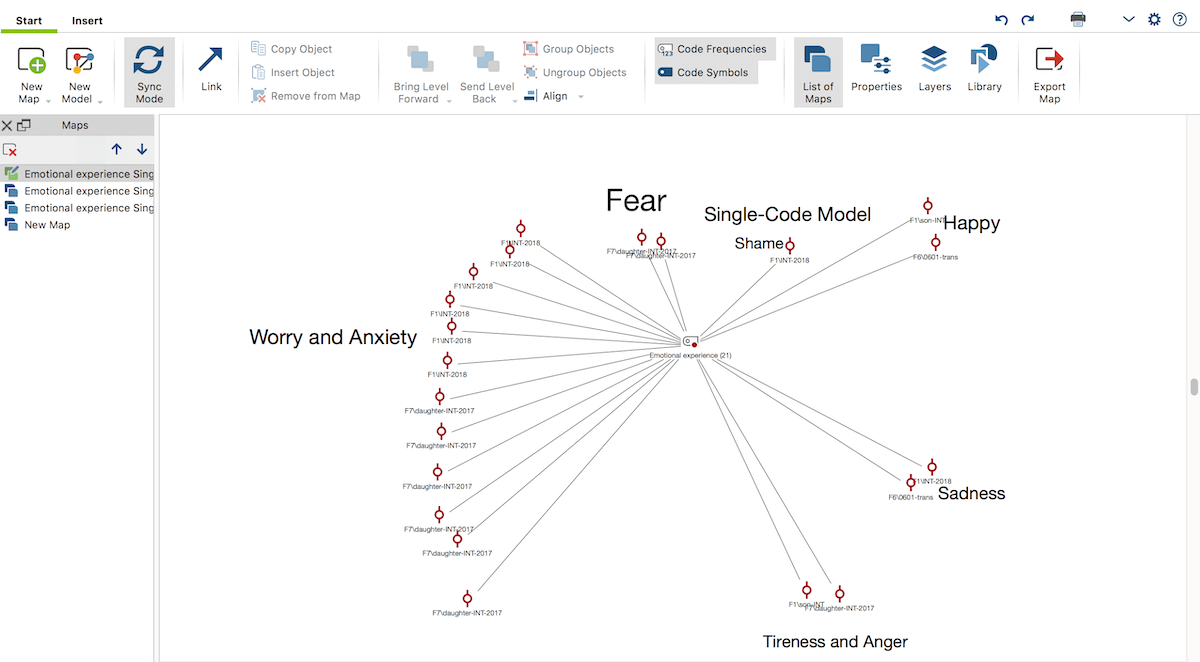
Break down broad codes with MAXMaps
Using the Smart Coding Tool to easily assign new subcodes
When I was ready to divide the broad parent code into subcodes, I used MAXQDA’s Smart Coding Tool to assign new subcodes to the activated segments under the broad code “Emotional experience”. The next step was then to think about how these particular emotions influenced choices and actions in the lives of my project’s research partners. To do this, I had to read my field notes carefully and examine the passage where I recorded observations of their daily routines, events, attitudes, emotions, and actions.
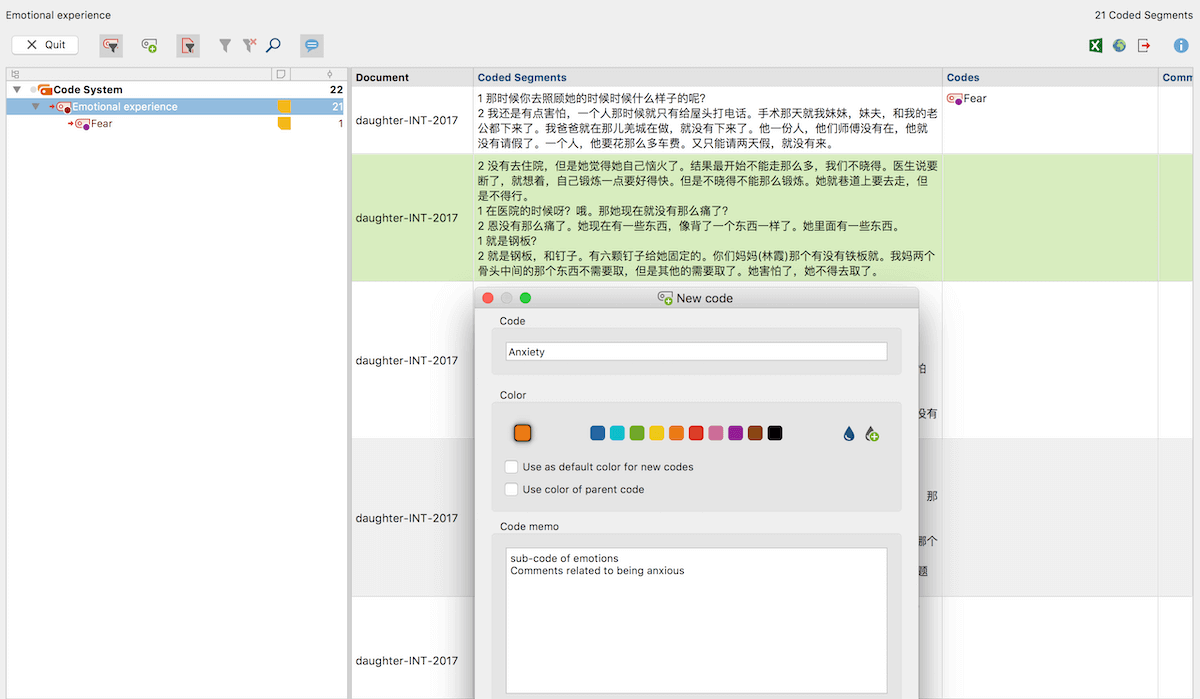
Assign new codes with the Smart Coding Tool
Separately Coding Field Notes and Interviews Transcripts
Given that I had already transcribed and coded my interviews with MAXQDA, I could already begin to categorize and analyze the coded segments in order to find thematic topics and patterns (as shown above). However, as I started to code my field notes for the first round to look for similar patterns, I quickly realized that the two kinds of materials were different in nature. My Professional MAXQDA Trainer consequently advised me to use different coding strategies when dealing with them.
Ethnographic field notes represent a different kind of material than interview transcripts for coding and analysis purposes. While I could assign socio-demographic variables concerning the interviewees (in one-on-one interviews) to my interview transcripts, I could not easily identify my field notes using document variables. This was because my field notes contained so many more dimensions, such as descriptions of people, circumstances, interactions, processes and so forth.
Merging projects to make connections with interview data
I therefore created additional code groups to identify facts and other aspects from my observations and applied them to all the relevant data segments. This greatly expanded the number of codes and made my Code System very complicated, so I decided to create a separate MAXQDA project for field notes. For example, in the field notes project, I created a group of subcodes under the parent code “Socio-demographic”, in which I included subcodes such as gender, age, education, migration status, and position in a family. I made another group of codes that contain thematic topics that came up inductively from the coding process. I also created an additional “family group” code to identify people in certain families if they also appeared in field notes about other families when they interacted.
Wherever applicable, I gave these thematic codes the same names as those in the interview project, which will help me recognize that they are about the same theme when I import the document groups into the main project later by using MAXQDA’s Merge Projects function.
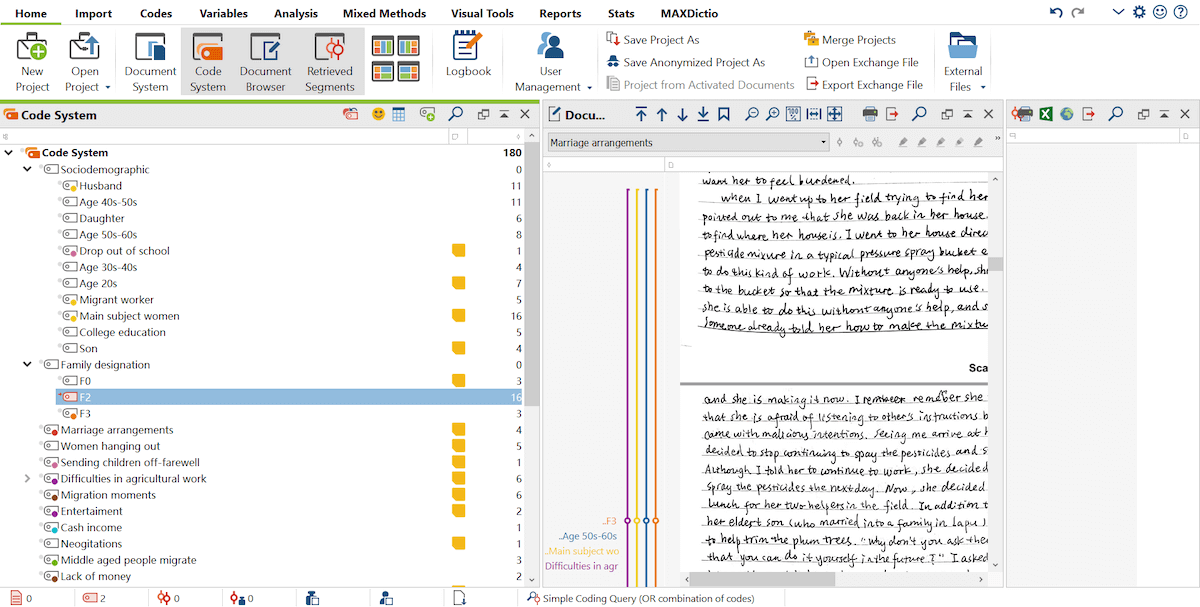
Create new groups of codes to identify facts in field notes
Finding co-occurrences with the Code Relations Browser
With all these different layers of codes, I decided to first use MAXQDA’s Code Relations Browser to look at the co-occurrences of various codes, especially the most frequent ones and think about how they related to one another. For example, I could identify if certain emotions such as “worry and anxiety” might co-occur with actions such as “transfer of money to migrants”. I then highlighted these segments when I went back to read them in the “Document Browser” window to understand the observations and circumstances when these emotions and actions took place.
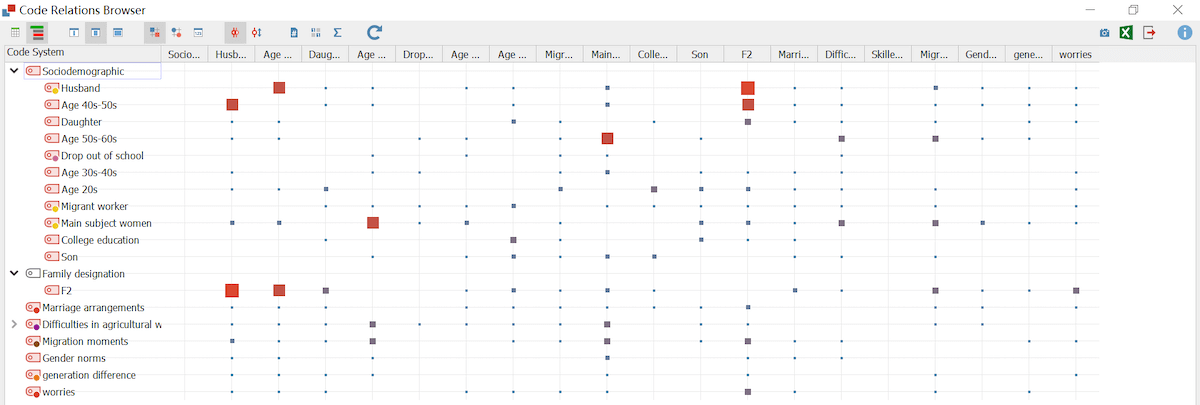
See co-occurrences with the Code Relations Browser
Using the Complex Coding Query to identify more specific intersections
Next, I performed a Complex Coding Query to identify more specific intersections in the coding. More specifically, I used specific codes under the socio-demographic dimensions to see, for example, if daughters and sons who migrated had similar or different experiences regarding marriage arrangements from their families.
I activated corresponding documents, codes including “daughter” or “son”, “marriage arrangements”, and other related codes such as “parental pressures”, or “conflict”. I could then locate specific intersections between the codes (circumstances and emotions) and read them again more closely in the “Document Browser” window.
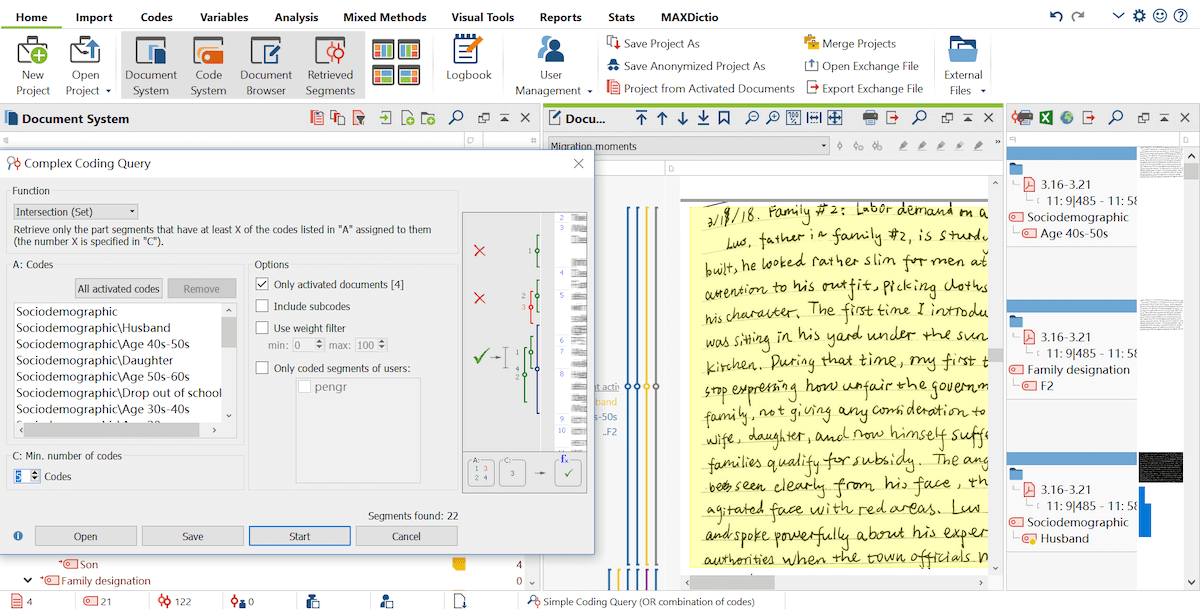
Find specific intersections with the Complex Coding Query
Because I had labeled my codes the same way in both projects, I could then read the data segments in the interview data project that corresponded with the specific codes assigned in the field notes project I was looking at. This process allowed me to compare if what research participants talked about matched or contradicted my observations. This comparison then helped me generate thematic and methodological insights for my future writing process.
Moving Forward: Identifying Patterns and Locating Negative Cases
Currently, I am reading two projects and comparing them against each other, using field notes to help me think through the interview data and vice versa. I use the Code Relations Browser and Complex Coding Queries a lot to identify patterns and differences, then I write memos and create charts to represent these patterns. This is very useful for me because by knowing the patterns, I can start to generate theories to explain the patterns and also systematically identify cases do not fit the theories yet. This helps me think theoretically about what cases I need to further investigate in order to help me understand the cases of interest.
The cases that fall outside of the pattern and explanations are termed “negative cases” by sociologists doing ethnographic research, and they help enrich case studies and test whether or not the theories and explanations we have developed stand. One of the most valuable takeaways I get from coding in this phase is identifying negative cases. By seeing the trends and explanations I have developed from previous observations and interviews, I can apply them to negative cases, and see why they do or do not fit with such explanations. This process has also helped me identify cases that need further investigation in the study.
For example, I found that I have not spent enough time with a couple of young people who have remained in the village instead of migrating (as the rest of their peers do). I subsequently observed their daily routines and did interviews with one young man to understand their lives in the village.

In this stage, I am actively using coding as a way to guide me through the last phase of data collection. I look forward to using mixed method functions next to generate systematic and cool visual representations of data and analysis.
Editor’s Note
Ruijie Peng is a recipient of MAXQDA’s 2017 #ResearchforChange Grant. She is a PhD candidate in Sociology at the University of Texas at Austin, USA. Her research project titled, “Home Support in Rural-Urban Migration” includes a 12-month ethnographic fieldwork period, which began in February 2018 in China. This is her third and final fieldwork diary entry. Follow Ruijie’s entire research journey with MAXQDA so far through her previous posts and stay tuned to hear more at the end of her project in 2019!