This week’s blog is all about autocoding. Autocoding means that MAXQDA creates one (or more codes) and automatically assigns ALL text passages (that fit) to these codes. For example, these codes can originate from keywords, hashtags, speakers and so on.
The autocoding function has proven to be a valuable tool in many research contexts, as it can save you a lot of time and guarantees that you don’t overlook any occurrence of the string you are interested in. In addition, MAXQDA offers advanced autocoding features, for example to facilitate the analysis of social media data.
In the following we will present some of the many research contexts for which autocoding is especially suited as well as some of MAXQDA’s advanced autocoding possibilities to give you some ideas about how you can use autocoding to enhance your research.
Use autocoding when importing your data
 The Import tab in MAXQDA
The Import tab in MAXQDA
Autocoding possibilities have been integrated in the import dialogue for many forms of data that you can analyze with MAXQDA. This means that even before you have had a look at the data, MAXQDA is there to facilitate the process.
Survey Data
Surveys are a valuable tool when it comes down to quickly and efficiently measuring the opinions of many people in a standardized way. Consequently, surveys are not only used in research contexts but also in the private sector, for example to assess the job satisfaction of employees. You can integrate data that you have collected through a survey in MAXQDA, either as an Excel spreadsheet or directly from SurveyMonkey. During the import process, you can choose for each survey question whether the corresponding responses should be imported/treated as a variable or as a code. As a rule of thumb, numerical variables, such as scores on a questionnaire item, are imported as document variables. Open-ended questions – questions that require a written/textual response – are imported as codes, but of course you are free to choose as there might be cases that are an exception to this rule. After clicking OK, MAXQDA creates codes for the selected questions and autocodes the corresponding responses.
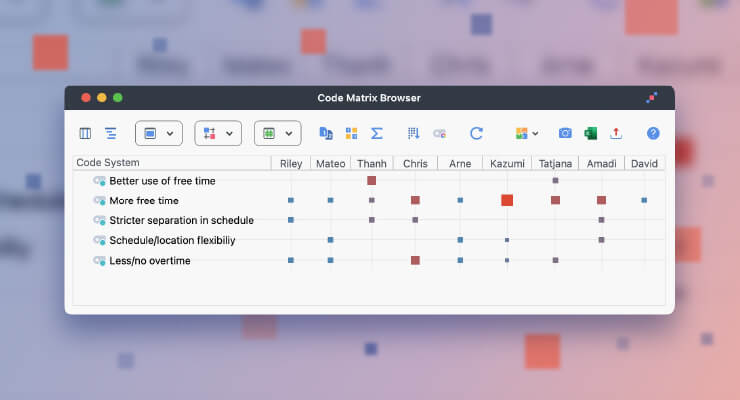
You can then view all responses to a certain question at once in the Retrieved Segments window and compare the answers or display only responses of a subset of people who fulfill a certain criterion (see Activate via variable) . For example, in order to find out what flexible work arrangements people prefer, one could activate only those documents of people that are at least satisfied with the flexible working arrangements and compare their response to the open-ended question.
 Autocoded responses to the open-ended question on types of flexible working arrangements of people who stated that they are at least satisfied with the flexible work arrangements.
Autocoded responses to the open-ended question on types of flexible working arrangements of people who stated that they are at least satisfied with the flexible work arrangements.
Of course, MAXQDA offers many more possibilities to dive deeper into your material. If you are interested, check out the following resources: (about the analysis of open-ended questions)
Two more resources to dive deeper into the analysis of survey responses are the following blog article by MAXQDA Professional Trainer Matthew Loxton and guide by Stefan Rädiker and Udo Kuckartz:
Focus Group Transcripts
Another useful autocoding function that applies upon import is the automatic coding of Focus Group Transcripts (a transcript of an interview with small groups). The interviewed participants can represent a certain target population and can build on each other’s responses which can result in fruitful discussions. When importing a Focus Group Transcript into MAXQDA, MAXQDA automatically recognizes the speakers and creates codes for each participant. The text segments of the focus group transcript will be autocoded with the code of the associate speaker. In this way it becomes immediately clear who spoke, how frequently, and how extensive the respective contributions are.-
 Autocoded result of the Focus Group import
Autocoded result of the Focus Group import
Furthermore, you can use “activations” to compile and compare the contributions of a single speaker or a selected subset of participants. For example, if you have stored background information on the speakers, such as age or level of experience, you can use “Activate via variable” to compare the responses of speakers of the same age.
Visit our blog article on analyzing virtual focus groups to learn more about autocoding focus groups and the analysis of focus groups in general:
Analyzing Virtual Focus Groups
Bibliographic data
When doing a literature review, for example in the context of a thesis, you are likely to come across bibliographic data and reference management programs, such as Endnote, Mendeley, or Zotero. With MAXQDA you can import bibliographic data and link it to the corresponding (full-text) PDF. Of course, MAXQDA facilitates analysis by autocoding tags and keywords (as explained in the following).
When imported into MAXQDA, each literature entry becomes its own text document which basically consists of a list of tags, such as author, title, publication date, and so on. MAXQDA automatically creates codes for these tags and assigns the codes to the corresponding literature entries. As such you can easily compile the abstracts of your literature, for example. In addition, many scientific papers contain keywords which summarize the topic and/or the methods used in the study. During import you can choose to also autocode these keywords. By activating all literature documents and a certain keyword, such as “happiness” and “questionnaire”, you can focus your analysis on only those papers which assessed “happiness” using a questionnaire.
 Autocoded result of the import of bibliographic data
Autocoded result of the import of bibliographic data
Social Media Data
YouTube Data
Autocoding during import can also be performed for YouTube comments. MAXQDA creates codes for the type of comment (top-level comment vs. reply) and creates codes for the number of replies (e.g. 0 replies, 2 replies, ….). This is especially helpful when you analyze videos with a large number of comments. By activating only those comments with a large number of replies, it is possible to focus your analysis on controversial comments and the discussion these comments initiated.
See how Daria Almeskirchen worked with her YouTube data here:
Non-sexist language in Russian: exploring Youtube with MAXQDA
Twitter data
The analysis of Tweets in particular can lead to large data corpora, including Tweets that are not really about the topic of interest. Therefore, you can choose if and which hashtags or authors of your data sample should be autocoded for further analyses.
 Select hashtags for autocoding
Select hashtags for autocoding
Use autocoding to facilitate your analysis
MAXQDA offers plenty of ways to facilitate your data analysis. As you already know, autocoding is one of these features and is implemented in many of MAXQDA’s tools. In particular, when analyzing large amounts of text it can be useful to use autocoding to quickly and efficiently identify important text passages.
Lexical Search
The Lexical Search function is probably one of the tools most often used during analysis. It allows you to search for keywords or keyword combinations and offers the possibility to autocode all text passages containing the searched-for keyword (or keyword combination). Using Lexical Search you can quickly and efficiently identify important text passages in your material without having to read all texts. Another advantage is that you eliminate the chance of overlooking any occurrence of your keyword/keyword combination. When autocoded, you can easily compile and compare these important text passages, for example to compare the definitions of a certain term between authors when doing a literature review.
The Lexical search function is described in more detail in the following blog posts:
Autocode with dictionary
A more advanced version of the Lexical Search Function is included in the MAXDictio add-on, called Autocode with dictionary. In contrast to Lexical Search where single strings or keyword combinations are used, the Autocode with dictionary tool uses user-defined dictionaries which can contain many words all related to the same category. For example, you can define a dictionary called “close relationships”, which includes search items such as “child”, “son”, “parents”, and so on, and a dictionary called “distant relationships” that includes words like “nephew”, “colleague”, “cousins”, and so on.
 Example of a dictionary for the category “Close Relationships”
Example of a dictionary for the category “Close Relationships”
When running Autocode with dictionary, MAXQDA searches for the words contained in the dictionaries and auto-codes the search results with the title of the respective dictionary. In the example illustrated above, MAXQDA creates two codes, namely “close relationships” for all results for “child”, “son”, and so on, and “distant relationships”, including all results for “nephew”, “colleague”, and so on. This is a quick and efficient way to create broader thematic codes. In addition, this tool allows you to quickly compare the frequency of your categories.
Autocoding of sentiments
Since the free update MAXQDA 2020.4 the Twitter Analysis features have been complemented by a sentiment analysis which allows you to automatically assess the sentiments of tweets. In addition, you can auto-code the tweets with their sentiment rating.
 Codes for sentiment ratings in the Code System
Codes for sentiment ratings in the Code System
Using MAXQDA’s tool for sentiment analysis you don’t even have to read any of the Tweets to get a grasp of the public feeling towards a topic. By collecting tweets at different points in time, you can also track the development of public feeling over time.
 Distribution of sentiment ratings
Distribution of sentiment ratings
We hope that this article gave you some ideas on how you can apply autocoding in your research project. Of course, MAXQDA offers many more features and is suited for many more research contexts. Have a look at our other blog articles to get even more ideas on how to analyze your data.