This is the second blog post about my research conducted with MAXQDA on the identification and integration of Hungarian Jews living in Israel. In the frame of my PhD, I conducted 90 interviews including several subgroups (such as those who immigrated in the 1990s, 2000s, those who returned and the second generation). This particular blog post deals with the 17 interviews which were taken with those whose parents emigrated to Israel before and after World War II.
Coding the use of various languages
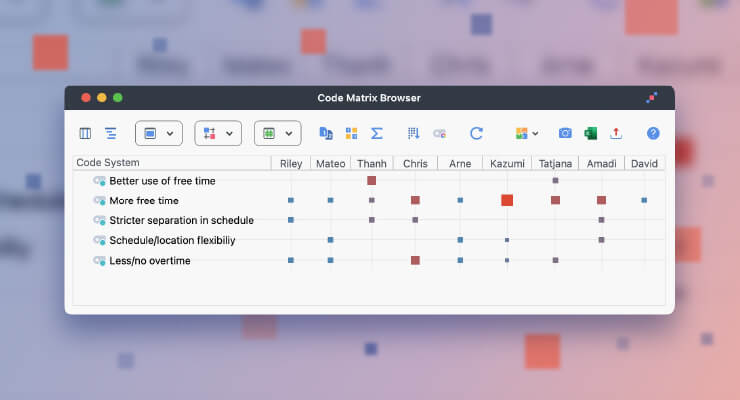
As most of these interviews were conducted in English because the interviewees do not speak Hungarian (or at least not fluently), I created a code “in Hungarian” which was used for those segments where they used Hungarian words, expressions, etc. (I used a similar technique for interviews conducted in Hungarian for passages where interviewees used English language, see my first blog post). When I transcribed the English interviews I marked passages with “(in Hung)” and put a slash before the first Hungarian word used in the sentence: see below. After coding the whole text, I searched for “in Hung” with the lexical search function and coded all the segments manually, since the number of words differed in each case.

The code “in Hung” marks Hungarian expressions in English interviews
Using MAXMaps to visualize the results
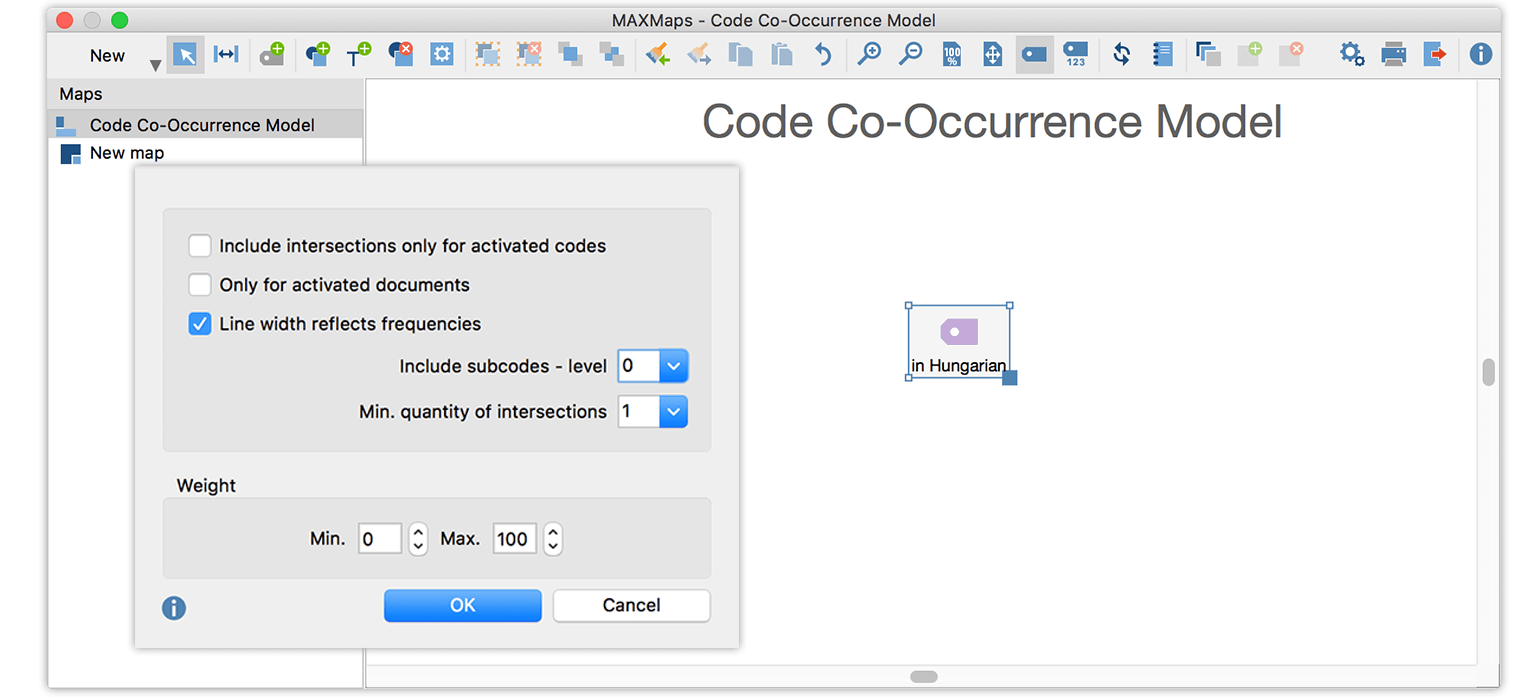
Now I wanted to find out in which contexts these Hungarian words came up the most often, i.e. which code they intersected with the most. To achieve this goal, I utilized MAXMaps. I opened a new “Code Co-Occurrence Model”, dragged the code “in Hungarian” on the map and checked the option “Line width reflects frequencies”.
Having done this, I received the picture below, which visualizes the frequencies of intersections between the use of Hungarian language and various codes through the thickness of the connection between them.
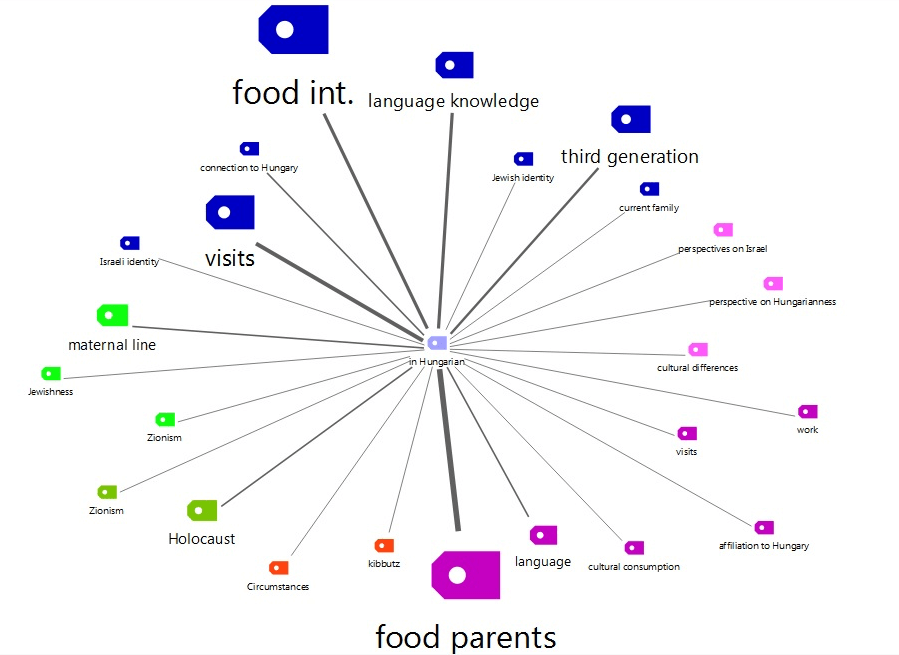
MAXMaps visualizes the frequencies of intersections between Hungarian language and various codes through the line width
The map clearly shows that the interconnections between Hungarian Language and the following codes are relevant for my research (in order of frequency):
- “Food int”: when the interviewee talks about whether he or she cooks/eats Hungarian food.
- “Food parents”: when the interviewee talks about whether his or her parents cooked Hungarian food. Here they would mention dishes.
- “Language knowledge”: when the discussion is about his or her language knowledge. They would show off their Hungarian knowledge and gave me some examples what words they knew (counting, etc.).
- “Holocaust”: when it is about how the parents survived the Holocaust. They used the words such as “labour camp” in Hungarian.
- And “third generation”: when they talk about their children. They knew words in Hungarian such as “come here” or “sweetie” which they would tell their children in Hungarian.
Previous research projects discovered that the second generation Hungarian immigrants in Israel usually did not keep their language for several reasons, but this finding might give us a more detailed insight. Even though it is not based on a representative sample, some of these factors (e.g. Holocaust) coincide with the characteristic of the Hungarian Jewry and some (e.g. food) are similar to other second generational immigrant groups’ identification.
About the author
Rachel Suranyi has been using MAXQDA for her research project for five years. She is a PhD student in the Social Science department at the Eötvös Loránd University in Budapest (Hungary) and participates in different research projects (including qualitative methods). Her research interests are focussed on migration and integration.
 Rachel Suranyi has been using MAXQDA for her research project for five years. She is a PhD student in the Social Science department at the Eötvös Loránd University in Budapest (Hungary) and participates in different research projects (including qualitative methods). Her research interests are focussed on migration and integration.
Rachel Suranyi has been using MAXQDA for her research project for five years. She is a PhD student in the Social Science department at the Eötvös Loránd University in Budapest (Hungary) and participates in different research projects (including qualitative methods). Her research interests are focussed on migration and integration.Want to know more about MAXMaps?
Watch our video tutorial!