This is a guest article written by Michael C. Gizzi, Ph.D (Professor, Illinois State University – mgizzi@ilstu.edu)
MAXQDA has transformed how I conduct research. I am a criminal justice and constitutional law scholar, who studies the impact and implementation of judicial policies. I seek to understand how lower courts interpret judicial policies established by the U.S. Supreme Court. This is done through a review of dozens and often hundreds of decisions from lower courts that seek to interpret, modify, and apply the higher court’s policy and precedent. My work in this area is currently focused on searches by police of vehicles using narcotics trained dogs.

In this blog entry, I am going to use a recent study as a way to illustrate the four-step research process that I use with MAXQDA. While the examples are from legal research, this process can be used by scholars in many areas.
The Four Stages of Research
The methodology I follow in conducting this type of research can best be described with a four-stage flowchart.
Stage 1
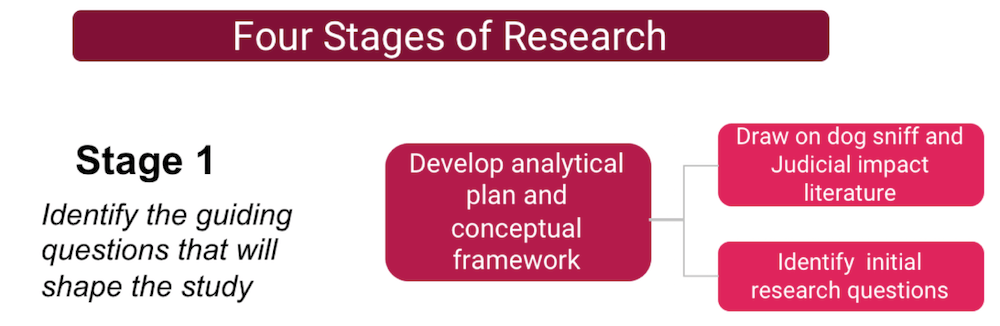
The initial stage is really no different from that of any other research project. You develop an analytical plan and conceptual framework for the research, by identifying initial research questions and conducting a literature review. For a judicial impact study on the reliability of narcotics dog sniffs, it means starting first with the legal precedents that frame the law, in this instance Florida v. Harris (2013), and Illinois v. Caballes (2005), which established the original precedents for dog sniffs.
The Harris decision suggests that defendants have the right to challenge the reliability of a narcotics dog and provides some guidance for judges to follow. The initial research question raised by Harris is “how the ability of defendants to challenge a narcotics dog’s reliability has impacted police use of dog sniffs?”
The literature review provides an initial set of issues to look at in exploring dog sniff reliability, such as false-alerts, where a dog alerts on contraband, but none is found, unintentional cueing of the animal by a handler, in which the dog wants to please its master, and residual contraband that a dog might alert on.
Stage 2
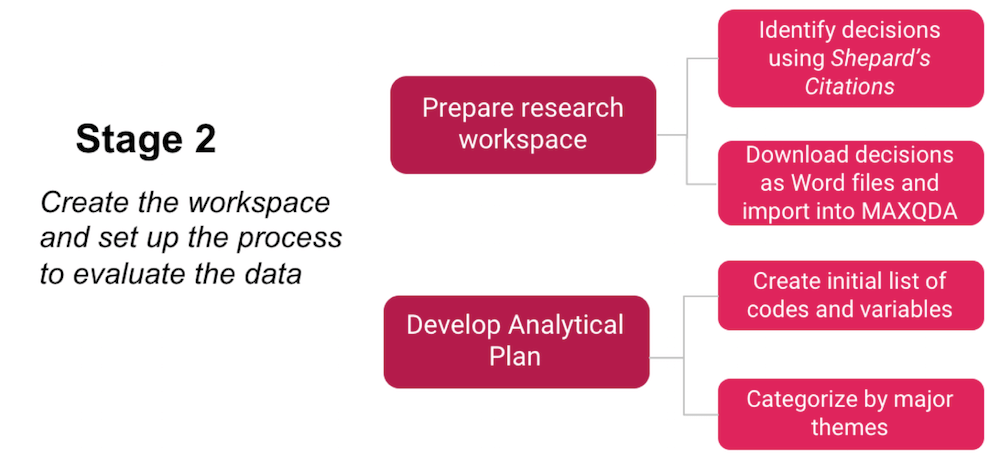
The second stage of the research process is where the literature review meets the research design. Judicial impact studies require the researcher to identify a population of judicial decisions that interpret the policy precedent. This is done using Shepard’s Citations®, a tool offered through the Lexis database. The case citation for Harris is entered into Shepard’s and it produces a list of decisions that have cited the decision, followed the precedent, or criticized it in some way. This list is organized by individual lower courts, and each case can then be downloaded. I limit the analysis to cases in which some analysis is made, as a mere citation in a subsequent decision might have no actual relevance to dog sniffs.
Once downloaded into Microsoft Word (or RTF) files, the cases are ready to be imported into a MAXQDA project, and a workspace is established. When doing this, I usually create a parallel spreadsheet that lists the name of the case, the court involved, the type of court (appellate vs. trial, for example), and other basic descriptors, which are then imported into MAXQDA as document variables.
Each document is numbered consecutively and imported into MAXQDA.
Once the cases are in MAXQDA, an initial set of codes and variables are created.

The code-list is drawn from the literature review and can be thought of as rather tentative. I’ll admit there are times when I just start with no code-book and read through a few documents, and then code on the fly (by right-clicking and selecting new code). Ideally, however, an initial code-book can help the coding process, and save time. I also try to organize the codes into categories, such as legal theories, legal concepts/standards, judicial criticisms, and factual information about the case (type of dog sniff, location of the stop, descriptions of the suspect and vehicle, and miscellaneous things). I always include a code for “quotable” (referring to language I am certain I will want to quote in the analysis). It is a catch-all code, but one that can be very valuable, especially when sorting through 40 or 50 documents.

Stage 3
Once the workspace is established the real work can begin; what I consider Stage 3 in the research process, the thematic analysis of cases. I begin this by doing a first read-through of a sample of documents, which serves to refine the code-book, and then I finalize the list of document variables. The goal here is to initially make sure that the code system and variables capture the elements necessary to help answer the research questions. In addition to reading and coding, I also use MAXQDA’s auto-code feature to select some of the key themes.
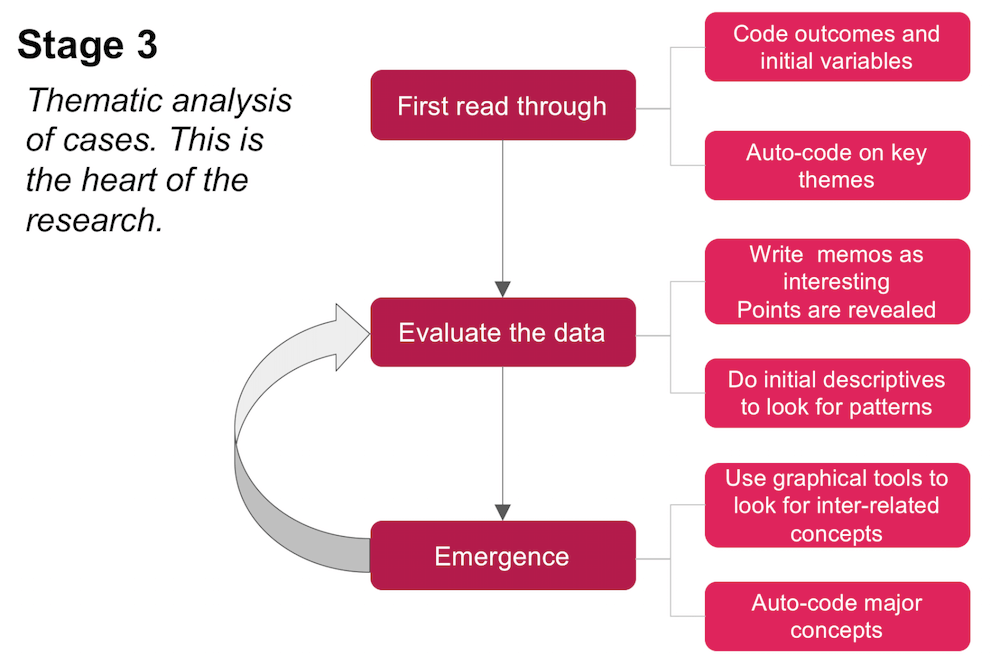
For example, when I read the first few documents in this study, it became clear that some courts took the testimony of expert witnesses very seriously, so I used the auto-code feature to search for ‘expert witness’, coding any usage of that word, within a paragraph afterwards. I repeated this for several other concepts I knew I needed to look for, like field performance, and handler cueing of dog behavior.
My general approach is to read through all the cases once, while coding them, and create either memos tied to documents, or free memos to take notes as I progress through the process. I then use MAXQDA’s analytical tools to look first at the descriptive statistics of what I coded. This is often an emergent process, and it certainly differs from project to project, but I try to look at the data in multiple ways, and look for unexpected patterns, and then take advantage of more of the advanced tools.
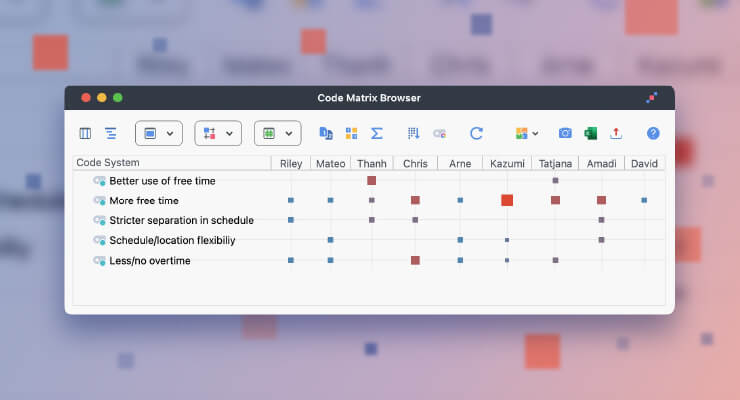
For example, in this project, one of the issues I was exploring was the role of a dog’s “field performance” as opposed to its formal training. I wanted to understand how lower courts treated a dog’s field performance records (e.g., how frequently the dog alerted, but no contraband was found) in light of the policy established in Harris.
Keyword in Context: MAXDictio
One of the tools I used was the “keyword in context” tool in MAXDictio, in which I looked at each coding of the world “field performance” by looking at the sentence before and after the term “field performance” occurred. This was valuable as it provided me with context, not only for how frequently the concept appears in decisions but also how it is dealt with. I then looked at coded segments for the term “field performance data” and was able to go deeper, looking at what I had coded, again seeking to get a more comprehensive understanding of how the courts viewed the concept.

Coded Segments

Finally, I created a Code Co-Occurrence model in MAXMaps, to see how my coding inter-related. The model by itself wasn’t essential to the research, but it helped me visualize inter-relations. For example, in thirteen cases that involved field performance data, there were 49 references to dogs “providing a cue” (where the dog’s behavior was influenced by the handler).
Code Co-Occurrence Model: MAXMaps
There are many other tools that can be used, and the more experienced you get with MAXQDA, the more likely you are to identify the tools that will best serve your needs. For me, visualizing the judicial impact study was very valuable, and it did it in a way very different from a statistical analysis. Qualitative mixed methods research truly is emergent in that you look at data in ways that are very different from traditional statistical analyses.

Textual data, once coded in MAXQDA, can be viewed through numerous lenses, and that can provide insight that can be easily missed. Sometimes it results in finding unexpected patterns, or results in finding connections that might be otherwise missed. It might also open up new avenues for approaching issues. For example, in the Harris study, I found that I had numerous codes and comments about judges making statements critical of police action yet constrained by the law from doing anything about it. The more I looked at this part of the data, it became clear that there was a potential second study for this dataset, independent of the original project.
Stage 3 and 4

Stage 3 and 4 of the research process often meld together, as the thematic analysis leads into analysis of data, and then writing the paper. This, too, is a much more fluid process with MAXQDA, as I often find myself going back to the software, looking at my memos, and coded segments to pick the best examples to write about, while also drawing on descriptive statistics of codes and variables. I’ll often use descriptive statistics to help organize the analysis, but then do a deep-dive into MAXQDA to flesh it out.
In the end, my goal is to be able to tell a story using case examples to explain how a judicial policy has been implemented. In my field of study, the vast majority of scholars take an entirely quantitative approach. MAXQDA provides me with a means to explore judicial impact with mixed methods, and to tell stories with the data.
About the Author
Michael C. Gizzi is a professor of criminal justice at Illinois State University, in Normal, Illinois. He is a MAXQDA professional trainer and is available for consultations and workshops. His poster, “Harnessing the Power of MAXQDA for conducting judicial impact research” won the prize for best poster at MQIC: The MAXQDA International Conference in Berlin this past February.
 Michael C. Gizzi is a professor of criminal justice at Illinois State University, in Normal, Illinois. He is a
Michael C. Gizzi is a professor of criminal justice at Illinois State University, in Normal, Illinois. He is a