This tip of the months was written by Elgen Sauerborn, who is a PhD student at the sociology department of the Freie Unversität Berlin, Germany.
I started my PhD on women in leadership positions and emotional labor in 2013. Working towards finishing my PhD involves reading lots of articles, papers and books over a long period of time. Because of the large amount of information I gathered it is important to have a simple and clear way to organize all the texts I want to use for my thesis.
I use MAXQDA for my PhD Thesis because it simplifies my way of working and guarantees to retrieve information fast and efficiently.
Import Literature
I work with two sorts of data: scientific articles and excerpts. The former I simply import (usually as a PDF-file) into my project. But sometimes, especially for complex sources I write an excerpt and add important quotes that could possibly be useful for my thesis. When adding quotes it is important to immediately make note of the page numbers to avoid searching for them a second time.
Furthermore, I create text documents for specific topics to add some single quotes or small text passages I come across during my research. In order to arrange the large number of documents neatly, I create themed document groups:

Create Codes Inspired by the Topics of your Thesis
The Code System I use is structured like the content of my Thesis:

If I work on single articles I simply code the passages that suit to the topics I’ve chosen. Basically, I work as if I am using a highlighter and a pen. It has the added-value that I not only mark the text segments but classify them concurrently. I often use the Memo Function within the document to note some ideas or questions that come to my mind.

Find all Information on a Particular Topic
After coding all my documents I use several ways to summarize the data I gathered.
First, I activate all the documents and single codes. Now I find all the information about one topic in the Retrieved Segments Window. If I want to compare what specific authors wrote about one topic I activate only the documents of the authors I want to work with.
Depending on what I want to find out I work with the Retrieved Segments Window (for a better overview of the content) or with the Coded Segments Window (to have a better overview of the authors):

Now, I have all the information I need at a glance.
IDENTIFY RELEVANT AUTHORS/TEXTS AND DEFICITS
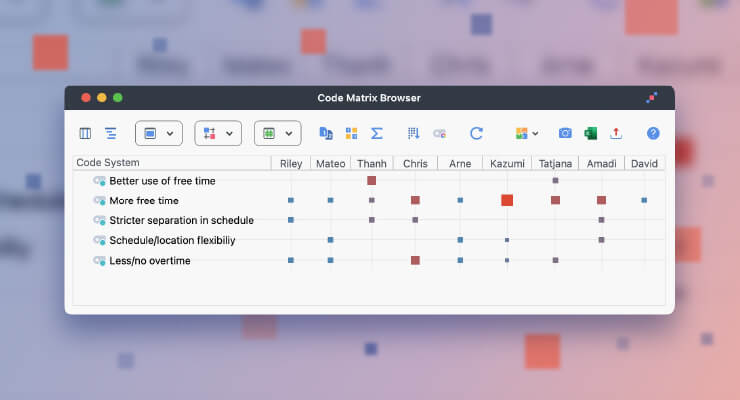
If I want to get an overview of all relevant authors and the information density of my literature I use the Code-Matrix-Browser (Visual Tools > Code-Matrix-Browser). It quickly shows me whether I’ve found comments for each topic. I can also see for which topics I need more information.

Tag relevant passages with the weight function
I use the weight function to mark relevant passages. MAXQDA allows me to assign a weight from 1 to 100 to every code. Currently I only use the numbers from 1 to 5.
If I call up the Coded Segments Window I can sort all passages by weights in order to have the most relevant passages at the top of my list. 
Extra Tipp
If I want to find out how certain variables – like year or place of publication – are related to the content of the articles, I also work with the variables function. For that I assign values for the variables (i.e. „2012“, 2006“ or „Germany“ „USA“) and transform the code(s) I want to work with into a categorical document variable. Now, the Data editor of the document variables shows me how the codes are related to Variables I created.
About Elgen Sauerborn

Elgen Sauerborn is a PhD-Candidate from the Department of Sociology at the Freie Universität Berlin. Her thesis is about women in leadership positions and emotional labor at the workplace. She is also part of the MAXQDA team where she among other things helps to organize the annual MAXQDA user conference CAQD.