Guest post by Maciej Talaga.
Corpus in linguistics refers to a body of documented instances of “real world” utterances, usually in a digitised form enabling processing its contents with computer-based tools. Thanks to their organic nature and size, corpora have proved very useful for various strands of linguistic studies (Stubbs, 2004; Baker, 2006), especially lexicography (e.g. pinpointing how words are actually used and understood), terminography (e.g. tracing how general language becomes turned into specialised jargon), or discourse analysis (e.g. revealing nuanced shifts in meaning of keywords formative for different narrations). It has also had a profound effect on historical linguistics and, in consequence, also on broader historiography (Kytö, 2011).
The present article will discuss elements of the corpus-based linguistic research used in an ongoing innovative project – Martial Culture in Medieval Towns – run by the Universität Bern, Switzerland, and funded by the Swiss National Science Foundation (2018-2022, project 178896). One of the case studies within the project deals with a peculiar historical document – an ordinance (Schulrecht) issued in the Swiss town of Solothurn to regulate a public teaching workshop delivered there in 1546 by a martial arts professional. What is unique in this document, among others, is that it contains a list of combat techniques which were to be taught during the event. The challenge, therefore, was to reconstruct these techniques or, in other words, identify the somatic/kinaesthetic content hidden behind their names. In effect, the study had to combine classical historical-linguistic investigation with so-called “embodied research” (Spatz, 2015). Such a combination posed several technical challenges, some of them very unusual, and pushed me to explore what MAXQDA offered in terms of solutions. Two such challenges shall be discussed below. Other, more typical aspects of our work with the software during the study are well covered in this article and therefore will not be addressed here.

Challenge One: The Secret Speech
During the project we investigated semantics of technical terms used by early-modern German-speaking fencing masters to refer to particular martial arts techniques they would promise to teach their students. The problem there was that the specialist literature (Fachliteratur) at the time routinely borrowed common words, such as names of everyday objects (e.g. pflug = plough or ochs = ox) or actions (e.g. heben = lifting or schiessen = shooting) and bestowed them with very narrow, specialised meanings pertaining to a particular area of expertise. Whether this was a deliberate choice aimed at protecting valuable know-how or an organic effect of building jargon from scratch is unclear, but nevertheless this process resulted in texts written in what already in the Middle Ages would be called “secret speech” (vordeckte rede; Bauer, 2016).
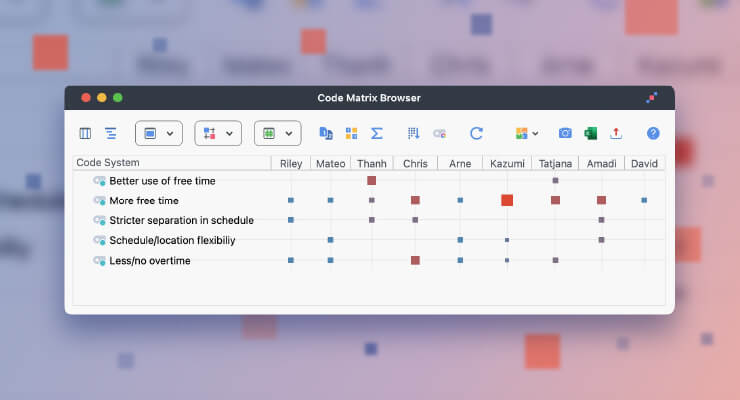
As a result, we were challenged to pinpoint the expert semantic context of the investigated terms. We approached this by performing a broad-based comparative study on relevant Fachliteratur – namely the so-called German fight books (Fechtbücher), didactic works written by master swordsmen (Bauer, 2016). Targeted lexical searches allowed us to code all instances of the investigated terms being used within their respective pragmatic contexts – e.g. whether they were used for describing martial techniques meant for armed or unarmed combat, associated with a particular weapon, or valued in a certain way (say, as a wise or a desperate thing to do). This strategy could be applied easily thanks to MAXQDA’s functionalities, such as the Code Relations Browser (Fig. 1) or Code Map (Fig. 2).
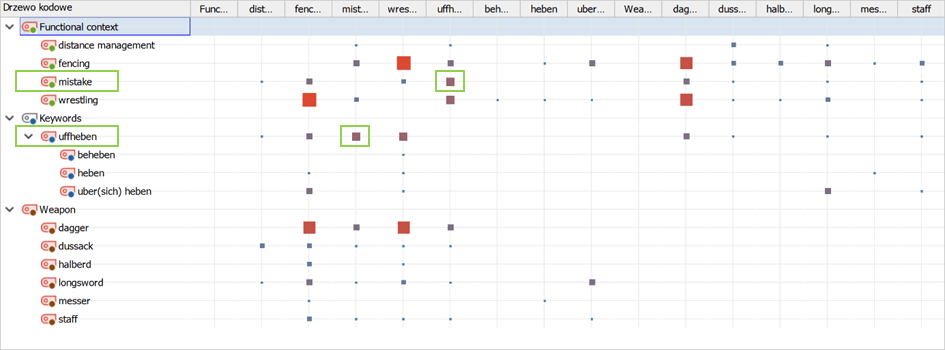
Figure 1.Code Relations Browser targeted at investigating the functional contexts of the term uffheben (marked in green). This chart helped us notice that although this term was very frequent in our sources and came in a variety of meanings, the majority of them were labelled as mistakes, i.e. errors that exposed a fencer during a fight. Given that we wanted to investigate uffheben as a valuable technique which a 16th-century Swiss fencing master was supposed to teach his students for a fee, we could then narrow down our search to these instances where this term was not labelled as a mistake and thus denoted a correct, useful move.
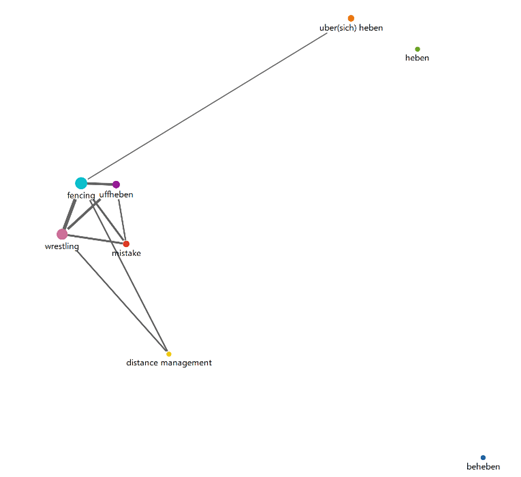
Figure 2. Code Map for the term uffheben reveals its functioning as a mistake in both unarmed (wrestling) and armed (fencing) combat techniques. At the same time it shows that its related terms – beheben, uber sich heben or the generic heben – were not used in this way.
The Code Relations Browser proved also useful in investigating differences in technical jargon used in historical sources. From the Code System panel it is possible to activate documents containing a specific code – in our case we could activate, for instance, all the sources tagged with the code wrestling and then explore how their terminology differed despite them dealing with very similar combat techniques (Fig. 3). This way it was also very easy to check for any subtle semantic differences between particular instances of the terms – the coded segments could be accessed directly from the browser by clicking the blue squares. While this thread was not explored in more detail during our project, it enabled outlining new research avenues for the future, such as the question of possible geographical or chronological trends in German martial arts terminology of the period.
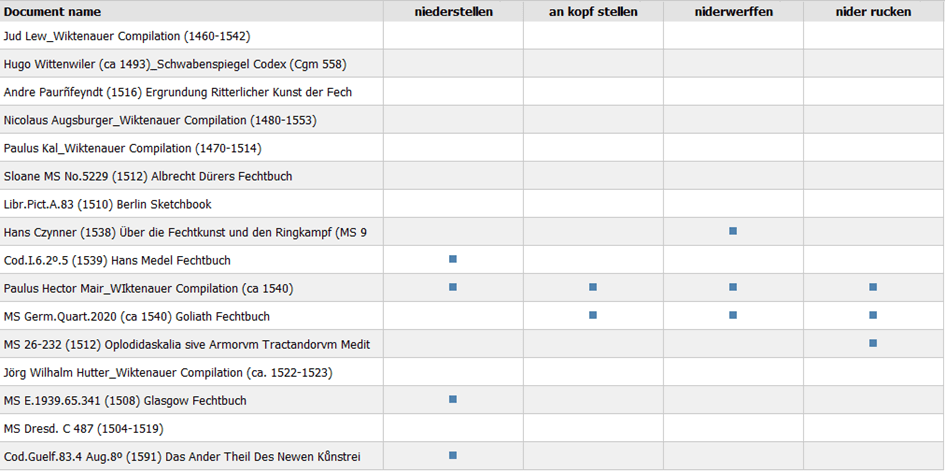
Figure 3. Code Relations Browser image generated from documents activated by the code wrestling for four technical terms. It clearly demonstrates that only half of the sources make use of these terms to speak about unarmed combat which suggests that there must have existed different synonymous expressions. Also, by clicking the blue squares the coded segments could be accessed directly from the Browser which greatly facilitated their exploration.
In the most complicated cases, deeper dives into the usage of the investigated terms were greatly facilitated by the Interactive Word Trees. Among the most notable features of this functionality is that it does not operate on codes, but on the raw text. Hence, it can be used both for preliminary exploration of the corpus, even before pre-coding, as well as at later stages of research. In our study, for instance, it enabled inferring a precise, specialist meaning ascribed in the investigated corpus to an inconspicuous combination of two extremely common words – “three pieces” (drei stücke). Interestingly, in this case Interactive Word Trees revealed multiple-level collocations, such as that between drei, stück, and winden (Fig. 4), thus enabling us to forge firm links between common phrases (drei stück) and technical-somatic terms (winden) much better-known from previous research (e.g. Farrell, 2015).
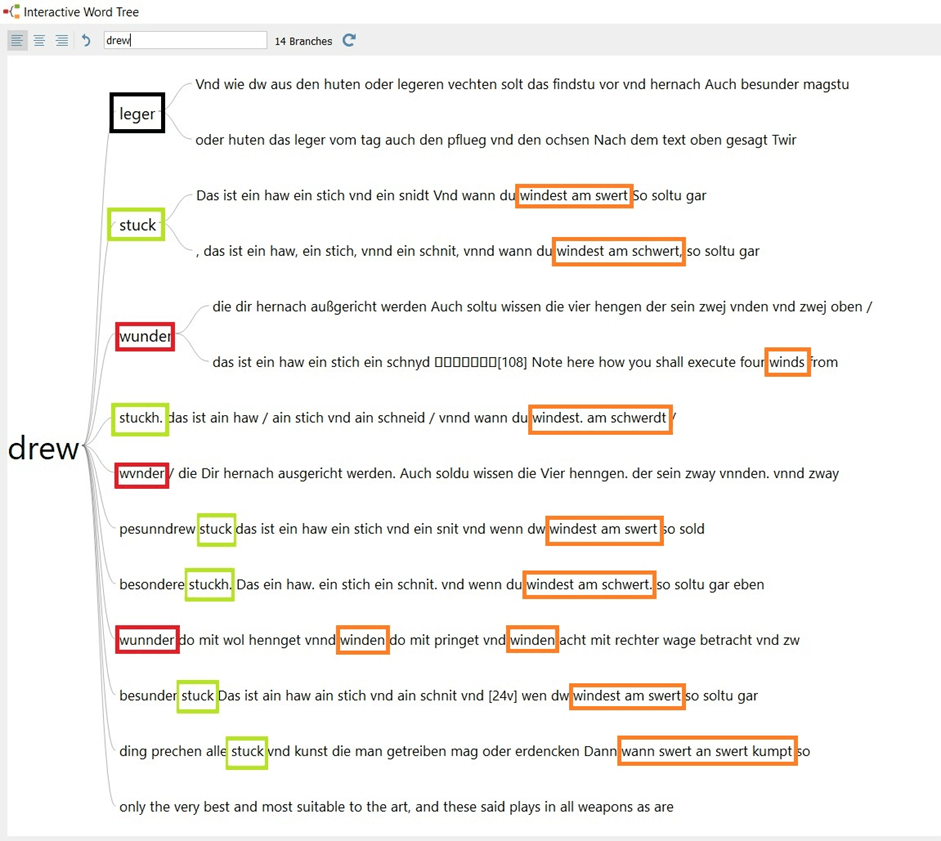
Figure 4. A sample Interactive Word Tree generated for the word „three” (here as drew which was one of the historical spellings). By carefully inspecting such Trees it was possible to clarify the meaning of the investigated phrase „three pieces” (drei stücke; marked in green) and even find new keywords collocating with the numeral „three” – here it was wunder, winden, and leger (marked in red, orange, and black, respectively). Note that drew, stuck, and winden formed a two-step collocation, since winden would not co-occur with either drew wunder or drew leger.
Learn more about Interactive Word Trees
Challenge Two: Messy Corpus
This study involved a lot of work with documents containing poorly-edited tables with the same text in multiple translations and sometimes also illustrations. Moreover, these documents had to be downloaded from an online repository and this did not always go smoothly – when copied to Word, document tables would often collapse. Bringing them back to a readable state manually would be a nuisance and waste of time. Fortunately, MAXQDA handled most of them pretty well (Fig. 5 and 6).
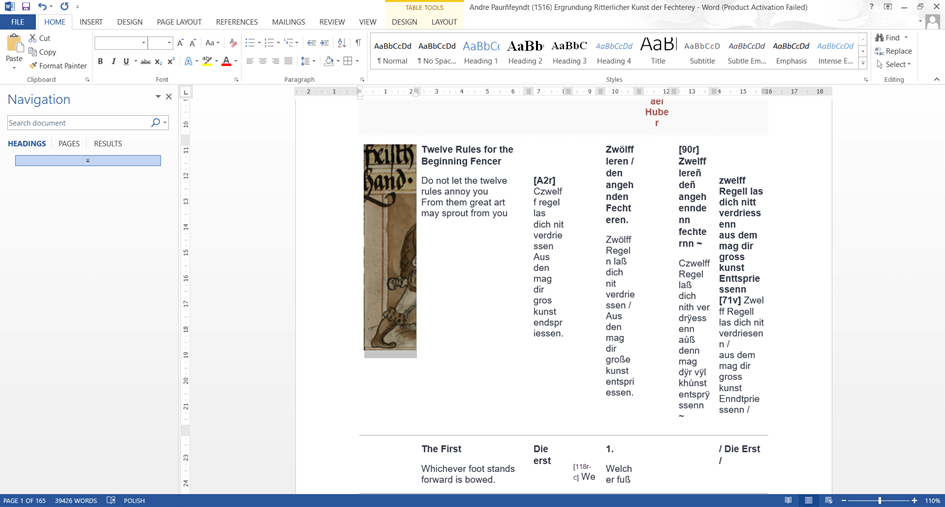
Figure 5. Data table directly after being downloaded and copied to Word. Not quite what was seen on the website.
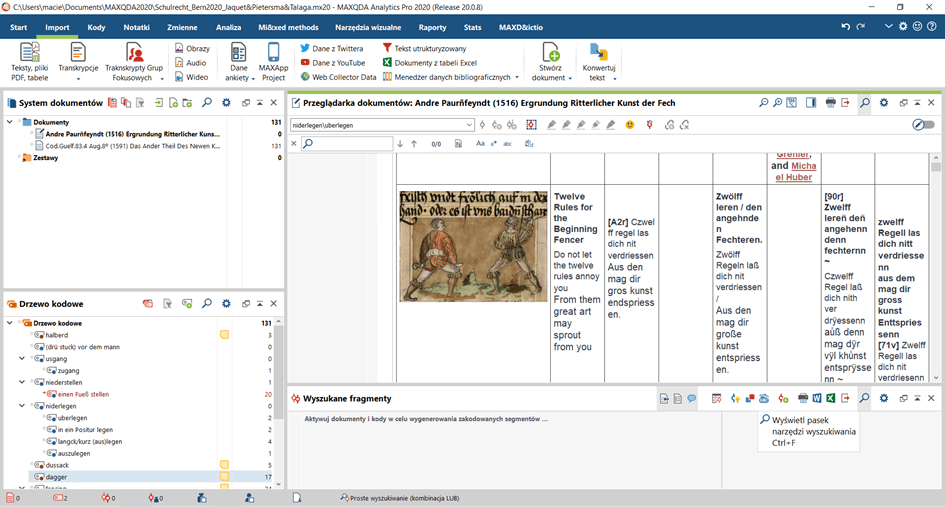
Figure 6. The same table opened in MAXQDA, without any changes in the Word document, results in an orderly and fully readable document.
During the last MAXQDA conference in Berlin (February 2020) I had an opportunity to attend a brilliant workshop on Qualitative Text Analysis by Daniel Rasch and there one of the participants asked him about possible uses of the Colour Highlight function. Daniel admitted he had never found a way to use it meaningfully and would love to learn one. Therefore, it seems worth mentioning here that in our project, quite specific as it is, this function turned out to be quite useful. Since each of our project documents juxtaposed several versions of the same text (different copies and/or translations) in comparison tables, we would normally mark and code interesting fragments in all the versions to be able to see them together in the retrieved fragments overview window (Fig. 7). However, sometimes versions of the coded text contained in the same document would differ in important details – for instance, when there was a mistake in translation or discrepancies between available copies of the text. In such cases, we used the colour highlight to mark the relevant fragments of the already coded text (Fig. 8). This was helpful especially in those documents where comparison tables were particularly broad – if we had used standard coding to mark the confusing fragments, the code would have been displayed beside the text and mixed with other codes ascribed to the fragment thus rendering locating the source of confusion very difficult. Conversely, when problematic fragments were coloured they were easy to spot without the need for clicking the relevant codes in the sidebar.
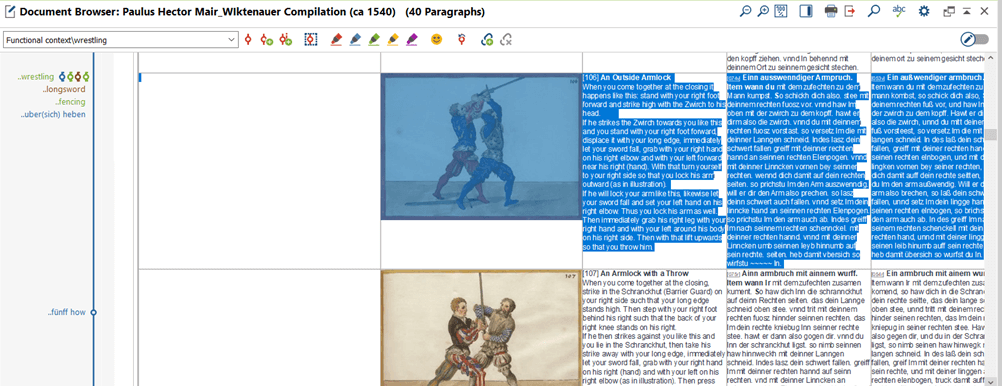
Figure 7. When a single table contains several versions of the same text as well as accompanying illustrations it is best to code all the columns together – this way the whole row is retrieved when needed. The downside to this method, however, is that it is extremely difficult to quickly locate the exact part of the text connected to the code or spot discrepancies between alternative versions of the text.
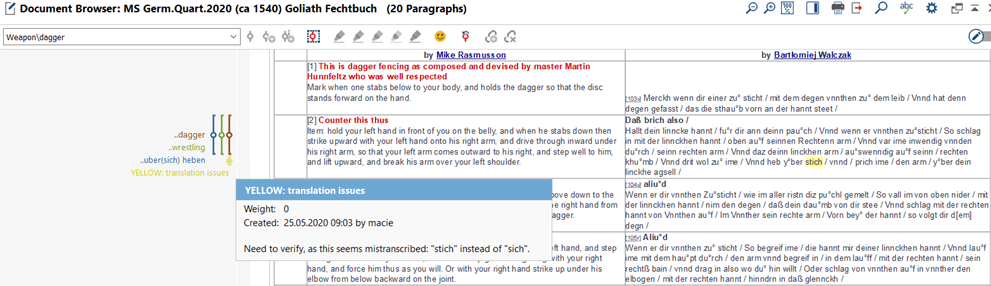
Figure 8. By using the Colour Highlight function it was possible to code whole rows of tables together while at the same time precisely distinguishing the relevant fragments visually (here highlighted in yellow). By adding comments to selections the highlights could be supplemented with easily-accessible additional information.
Closing Remarks
All in all, it has to be stressed that application of MAXQDA has been crucial for our project. It made our huge and technically challenging corpus manageable and greatly sped up the analytical process. Two of its somewhat less-prominent functionalities (Colour Highlight, handling tables in Document Browser) proved very helpful and served as a meaningful supplement to the more typical functionalities of the software.
Since the project presented here is still ongoing, no further conclusions can be stated at the moment.
Acknowledgments
I would like to use this opportunity to extend my gratitude to Daniel Jaquet, PhD, and Miente Pietersma, MA, for allowing me to share the technical aspects of our project here.
Literature references:
Baker, P. (2006). Using corpora in discourse analysis. A&C Black: London-New York.
Bauer, M. J. (2016). Teaching How to Fight with Encrypted Words: Linguistic Aspects of German Fencing and Wrestling Treatises of the Middle Ages and Early Modern Times. In D. Jaquet, K. Verelst & T. Dawson (eds), Late Medieval and Early Modern Fight Books (pp. 47–61). Brill: Leiden-Boston.
Farrell, K. (2015). The Kölner Fechtbuch: Context and Comparison. Acta Periodica Duellatorum, 3(1), 203–235.
Kytö, M. (2011). Corpora and historical linguistics. Revista Brasileira de Linguística Aplicada, 11(2), 417–457.
Stubbs, M. (2004). Language corpora. In A. Davies & C. Elder (eds), The handbook of applied linguistics (pp. 106–132). Blackwell Publishing: Malden-Oxford-Carlton.
About the Author
Maciej Talaga is a PhD candidate within the interdisciplinary post-graduate course “Nature Culture” at the Faculty “Artes Liberales” (University of Warsaw) and a member of the European Committee for Sport History (CESH) and the Society for Historical European Martial Arts Studies (SHEMAS). He investigates late-medieval and early-modern European martial culture and works to develop a praxiographic and embodied methodology for his research. He is also interested in applying computer-assisted qualitative analyses into his practice as an archaeologist-historian. You can learn more about the programme he is involved in here: Nature-Culture Programme
 Maciej Talaga is a PhD candidate within the interdisciplinary post-graduate course “Nature Culture” at the Faculty “Artes Liberales” (University of Warsaw) and a member of the European Committee for Sport History (CESH) and the Society for Historical European Martial Arts Studies (SHEMAS). He investigates late-medieval and early-modern European martial culture and works to develop a praxiographic and embodied methodology for his research. He is also interested in applying computer-assisted qualitative analyses into his practice as an archaeologist-historian. You can learn more about the programme he is involved in here:
Maciej Talaga is a PhD candidate within the interdisciplinary post-graduate course “Nature Culture” at the Faculty “Artes Liberales” (University of Warsaw) and a member of the European Committee for Sport History (CESH) and the Society for Historical European Martial Arts Studies (SHEMAS). He investigates late-medieval and early-modern European martial culture and works to develop a praxiographic and embodied methodology for his research. He is also interested in applying computer-assisted qualitative analyses into his practice as an archaeologist-historian. You can learn more about the programme he is involved in here: