Guest Post by Amélie Dumarcher.
Large sets of qualitative data: advantage or constraint?
Verbal and textual data are essential in social science research. However, the exploration of large data corpora requires significant investments, both in time and funds, limiting their use or making them dependent on substantial funding. In this context, where their richness is paradoxically an obstacle to knowledge, it seemed particularly interesting to examine the potential offered by both hybrid approaches of content analysis (manual and computer-assisted) and by mixed methods approaches to facilitate the analysis of these large textual data sets.

The project we’re introducing here is part of a larger effort to assess the potential of computer-assisted textual data analysis in our research fields. In a previous bibliographical analysis, we explored the use of automated lexical analysis to investigate scientific publications from members of a research group in territorial development (Fournis and Dumarcher, 2017).
This following project on environmental assessment aims 1) to deepen this exploration by examining the potential of semi-automated analysis tools available in some QDA software, such as MAXQDA, and 2) to explore combinations of computational tools, to see to what extent they optimize and facilitate the analysis of these large corpora.
Let’s start with a few words about the project, before explaining in more detail how we used MAXQDA.
The project: “Thinking like the BAPE. Expertise building at the Bureau d’Audiences Publiques sur l’Environnement (Quebec)”
In addition to the methodological goals we have just discussed, this project also aimed to increase our knowledge of the Bureau d’Audiences Publiques sur l’Environnement (BAPE), an independent environmental assessment and decision-making support agency of the Government of Quebec, Canada. More specifically, we wanted to study the structure of knowledge generated by public stakeholders during a development project – in this case, all reports produced by the BAPE related to wind farm projects in Quebec (briefs will be analyzed in the next part of the project).
Case study approach

We conducted a case study on the wind energy sector, using the 21 reports produced during public hearings from 1997-2016. The analysis aims to examine the joint evolution of the addressed issues (thematic content: technical, environmental, territorial issues) and the expertise mobilized and referenced (bibliographic content: public, private, citizens, technical, scientific expertise, etc.) The idea is to identify the socio-technical frameworks favored by public policy, as well as their variations and evolution according to projects and periods.
Methods
This study was therefore carried out in two parts – expertise and issues – corresponding to two methods:
- To explore the issues addressed in the reports, we used automated textual data analysis (with Iramuteq software).
- To examine the kinds of expertise involved in the 21 reports, we identified (semi-automatically with MAXQDA 2018) and analyzed the 5867 bibliographic and documentary references listed, as well as their 9192 citations through the text.
Let’s look in more detail how MAXQDA was successfully mobilized in this assessment of expertise.
Retrieving, coding and extracting quotes with MAXQDA
In practice, MAXQDA was used to retrieve, code and extract citations from reports. It was the extended lexical search function that allowed us to automatically retrieve quotes, with the use of wildcards and regular expressions. The citations were then coded with MAXQDA’s autocode function, depending on the type of document to which they refer.
The BAPE classifies documents into categories according to their source and intended purpose (procedural documents, submitted by the sponsor, by participants, transcripts of meetings, briefs, bibliography, etc.) These documents are referenced and classified in a relatively standardized format (letter chains and numbers), which has simplified the retrieval and automatic coding.
Our approach could be easily adaptable to the analysis of other semi-structured textual data (various administrative documents, scientific publications, etc.) We could also have used MAXQDA to analyze the issues addressed in the reports, but in accordance with our objective to explore the potential of automated and semi-automated content analysis approaches, we conducted an automatic lexical analysis with Iramuteq software.
Exploring coding results with MAXQDA’s visual tools
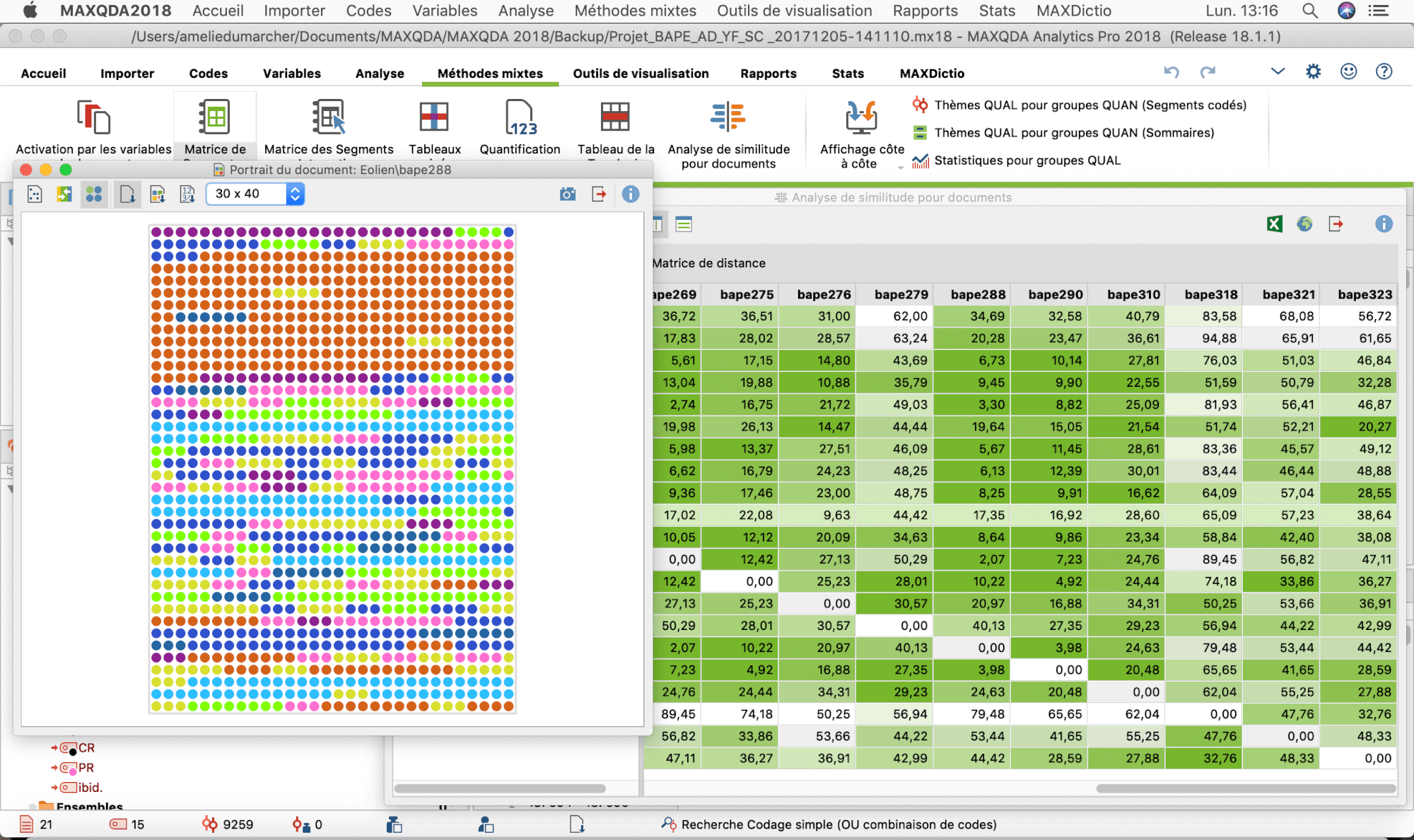
Document Portrait and Distance Matrix in MAXQDA
The coding results were then further explored with MAXQDA’s analysis and visualization tools: we examined similarities between reports (Code Matrix Browser, similarity and distance matrices), and compared the internal structure of the reports (Document Portrait). Using MAXQDA’s visual tools, we were able to shed light on the most frequently cited types of documents and associated trends but our analysis remained too limited because these results were based only on the BAPE documents’ classification: they only provided a very limited insight into our object.
We wanted to take this further and examine the types of expertise mobilized and the kinds of stakeholders involved. In this regard, we took advantage of MAXQDA’s rich export capabilities to carry out further analysis in a spreadsheet-based software. We built a database in the spreadsheet (working in a similar way to a – simplified – relational database), which links three entries:
- the BAPE reports (and their features),
- the bibliographical and documentary references listed in the reports (manually coded according to the type of expertise and stakeholder to which they refer: public, private, citizen, technical, scientific, etc.),
- citations of these references over the reports’ text, retrieved and already coded once through MAXQDA.
The export of the retrieved segments in MAXQDA also includes information on the location of the segments within the reports (start and end indicators). It thus allowed us to consider the evolution of the kinds of expertise mobilized over time, as well as the variations across projects and their characteristics. We were able to more clearly see the trends and changes, and distinct phases emerged over time as the wind energy sector was being structured.
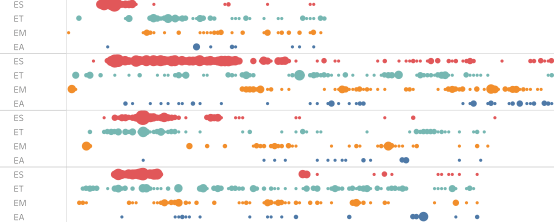
“Dialogue” between different kinds of expertise, through co-occurrence and density of quotes in reports
(made with Tableau Software, based on the exported retrieved segments from MAXQDA).
With some additional work on conversion and formatting, we were also able to visualize the density at which the different types of expertise are mobilized throughout the text of the reports, and their co-occurrence: it allowed us to see which kinds of expertise are mobilized jointly, in the form of “dialogue” (see illustration).
Results: the progressive stabilization of the wind energy sector
The results have shown that, consistent with our expectations, the structure of the mobilized expertise evolves over time in conjunction with the evolution of the addressed issues. There is thus a kind of progressive stabilization of the wind energy sector: the emergence and stabilization of successive issues, through the mobilization of various expertise, and with fluctuations in the extent of public participation.
This result seems to confirm the potential of mixed methods and hybrid approaches to content analysis, both for political science and policy analysis (as in this project) but also for bibliographic and bibliometric analysis (see the intersection between reference analysis and thematic analysis).
What’s Next?

We will further explore the potential of these methods in the next phase of the project, which will incorporate public participation: a content analysis of the briefs (submitted as part of the hearings processes) will be used to contrast the issues raised in the briefs with those outlined in the reports.
It is also planned to analyze the BAPE reports and briefs for other energy and resource sectors.
This project was conducted in collaboration with Yann Fournis (Université du Québec à Rimouski) and Sébastien Chailleux (Université de Pau et des Pays de l’Adour), with the financial contribution of the Centre de Recherche sur le Développement Territorial (CRDT). For more information on the project and to stay informed of updates, please visit the project webpage.
FOURNIS Yann and DUMARCHER Amélie, 2017. Le territoire du CRDT. La construction d’un espace intellectuel, entre science et territoire., Rimouski (QC): Éditions GRIDEQ-CRDT, 161 p.
CHAILLEUX Sébastien, DUMARCHER Amélie, FOURNIS Yann, 2017. La construction de l’expertise du Bureau d’Audiences Publiques sur l’Environnement (Québec) Le cas des projets éoliens (1997-2016)., presented at the « 14ème Congrès de l’AFSP », Montpellier (France).
About the Author
Amélie Dumarcher is a Professional MAXQDA Trainer with a background in applied geography (MA, Université d’Avignon – France), who is currently working on her PhD in Regional Science, with a Political Science orientation (Université du Québec à Rimouski – Canada). Her research focus on resource governance in Quebec and Canada, and on the historical development patterns and current trends of peripheral territories. She has a strong interest in multidisciplinary and mixed method approaches, and in the potential of computer-assisted approaches and tools for research.
 Amélie Dumarcher is a
Amélie Dumarcher is a



