Topic Modeling ist ein Verfahren aus der Welt des Natural Language Processsings (NLP). Mithilfe von unüberwachtem maschinellen Lernen werden Textdokumente statistisch auf Wortmuster hin analysiert, um Wörter in Gruppen (den sogenannten „Topics“) zusammenzustellen:
Topic Modeling in MAXQDA
Topic Modeling in MAXQDA dient vor allem der Exploration des Datenmaterials. Topic Modeling unterstützt Sie dabei, Themen in ihren Dokumenten oder Surveyantworten zu identifizieren und diese in Ihre Analyse einzubeziehen:
- Die identifizierten Topics lassen sich mit den jeweils zugehörigen Wörtern als Diktionär speichern. Das Diktionär können Sie dann für Autocodierungen und die diktionärsbasierte Inhaltsanalyse verwenden.
- Das bei jedem analysierten Dokument dominierende Thema lässt sich als Dokumentvariable festhalten.
- Die Dokumente lassen sich entsprechend der dominierenden Themen zu Dokumentsets zuordnen.
Empfohlener Ablauf von Topic Modeling in MAXQDA
Generell sollten Sie bei der Anwendung von Topic Modeling in MAXQDA folgende Schritte durchlaufen:
1. Vorbereitung: Stopp-Wort-Liste für die Daten anlegen
Verschaffen Sie sich mithilfe der Funktion MAXDictio > Worthäufigkeiten einen Überblick über die Wörter, die in den zu analysierenden Texten vorkommen. Transferieren Sie alle Wörter, die nicht sinntragend sind, in eine Stopp-Wort-Liste, um diese bei der späteren Analyse zu ignorieren.
2. Erstes Modell erstellen
Überlegen Sie mit Blick auf die analysierten Daten im Vorhinein, ob Sie eher mit vielen unterschiedlichen Topics rechnen oder mit wenigen. Je unterschiedlicher und vielfältiger die Dokumente in ihren Worten sind, desto größer sollte die Anzahl an Topics gewählt werden. In MAXQDA voreingestellt sind 6 Topics, was eher eine geringe Anzahl ist.
Erstellen Sie wie unten beschrieben das erste Topic-Modell.
3. Modell prüfen und bei Bedarf Alternativmodell erstellen
Überprüfen Sie die inhaltliche Kohärenz der einzelnen Topics und probieren Sie ggf. Alternativmodelle mit mehr oder weniger Topics aus. Zur Bewertung des Modells können Sie auch die Topic-Dokument-Matrix heranziehen, welche zeigt, mit welcher Wahrscheinlichkeit ein Topic bei einem Dokument vorkommt. Wenn in den Dokumenten jeweils mehrere Topics vertreten sind, obwohl sie thematisch nicht sehr vielfältig sind, dann ist vermutlich ein Modell mit mehr Topics besser geeignet.
Schließen Sie bei Bedarf weitere Wörter aus der Analyse aus, indem Sie diese ebenfalls in die Stopp-Wort-Liste einfügen.
Generell ist es hilfreich für die Interpretation, parallel zum Topic-Modelling-Fenster die Worthäufigkeiten zu öffnen, um zu überprüfen, in welchen Kontexten Wörter verwendet werden und wie häufig diese vorkommen.
4. Benennen Sie die Topics
Benennen Sie die Topics mit einem übergeordneten Begriff, der die darin enthaltenen Worte in abstrahierender Form zusammenfasst.
5. Anwendung und Sicherung der Topics
Halten Sie das dominante Topic pro Dokument automatisch als Dokumentvariable fest oder erzeugen Sie entsprechende Dokumentsets mit den jeweiligen Dokumenten. Legen Sie ein Diktionär mit den Wörtern pro Topic an.
Speichern Sie die Topics im Arbeitsbereich Questions – Themes – Theories (QTT) oder exportieren Sie diese zu Excel.
Voraussetzung für die Durchführung von Topic Modeling in MAXQDA
Um sinnvolle Ergebnisse bei Topic Modeling zu erhalten, ist es notwendig, dass nicht nur wenige Dokumente mit sehr ähnlichen häufigsten Wörtern analysiert werden. Mit weniger als 30 Dokumenten sind kaum inhaltlich bedeutsame Ergebnisse zu erwarten, bei Surveydaten von 100 Personen sind die Chancen schon größer.
Topic Modeling aufrufen
- Aktivieren Sie alle Dokumente, die Sie in die Analyse einbeziehen möchten.
- Starten Sie die Funktion MAXDictio > Topic Modeling.
- Nehmen Sie im Dialog die gewünschten Einstellungen vor:
- Anzahl der Topics
- Beschränkung auf bestimmte Dokumente oder Segmente
- Ignorieren von bestimmten Inhalten und Stopp-Wörtern
- Lemmatisierung (Reduktion der Wörter auf ihre Grundform)
Nach Klick auf OK startet die Berechnung. Topic Modeling ist ein sehr rechenintensives Verfahren und kann daher auch bei kleineren Datenmengen einige Minuten in Anspruch nehmen.
Tipps: (1) Sie können während der Berechnung mit anderen MAXQDA-Funktionen weiterarbeiten. Die Berechnung geht weiter, solange Sie das Fenster geöffnet lassen. (2) Wenn Sie das Fenster nach der Berechnung geschlossen haben, können Sie es über MAXDictio > Topic-Modeling > Letztes Ergebnis Topic-Modeling wieder öffnen.
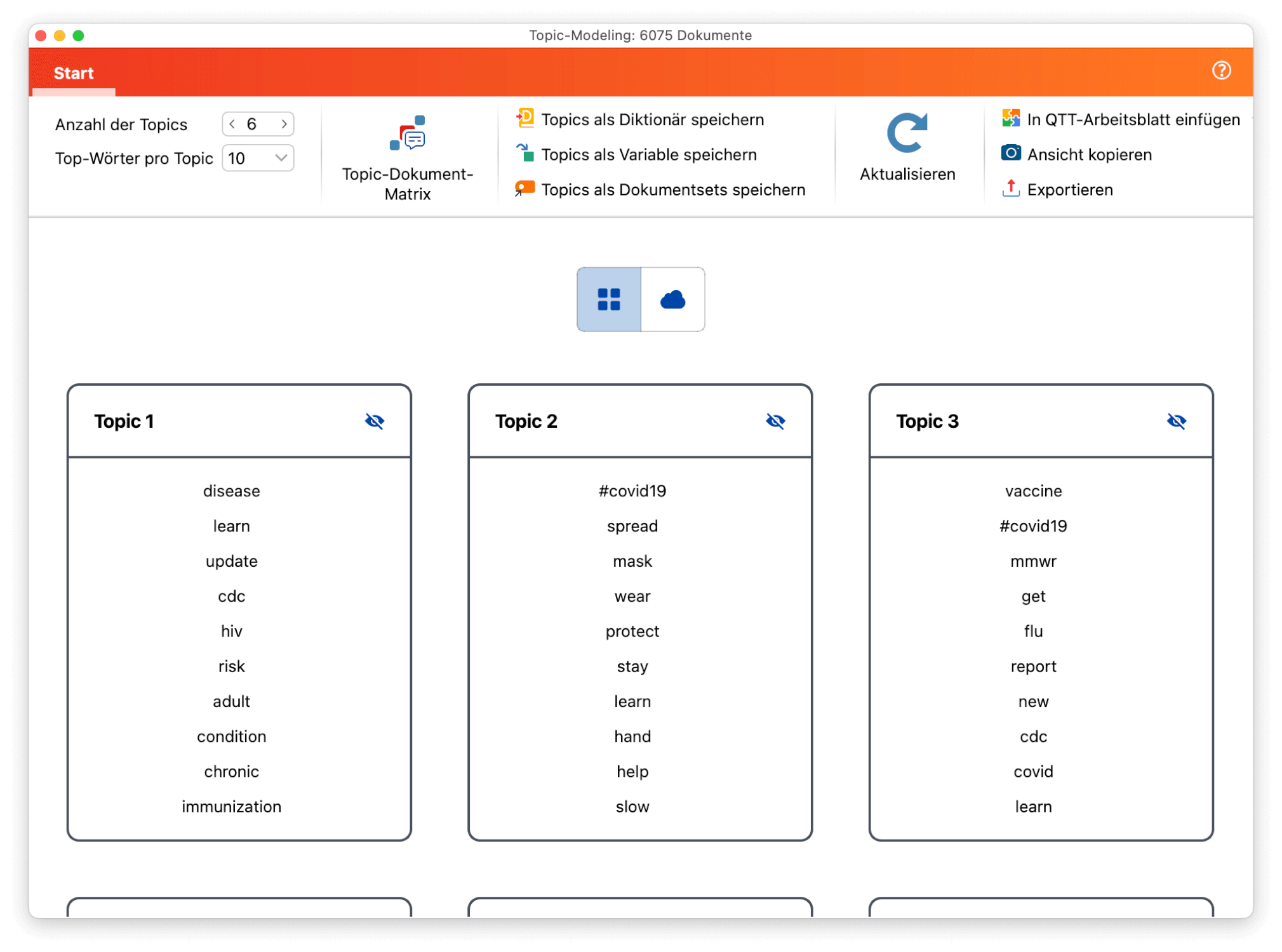
Das Ergebnisfenster
Im Ergebnisfenster werden die ermittelten Wörter pro Topic präsentiert:

Je wichtiger ein Wort für ein Topic ist, desto größer und farbiger wird es in der Wortwolke dargestellt und desto weiter oben steht es in der Listendarstellung.
Im Ergebnisfenster stehen Ihnen folgende Möglichkeiten zur Verfügung:
- Mithilfe der Symbole oberhalb der Topics können Sie die Ansicht von Liste zu Wortwolke umschalten.
- Um die einzelnen Topics zu benennen oder umzubenennen, klicken Sie auf den aktuellen Namen.
- Um ein Topic bei weiteren Analysen zu ignorieren, klicken Sie auf das durchgestrichene Augensymbol. Ausgeschaltete Topics werden in folgenden Funktionen ignoriert: „Topic-Dokument-Matrix“ und „Topics als Diktionär/Variable/Dokumentset speichern“.
- Oben links im Menüband kann die Anzahl der Topics und die Anzahl angezeigter Wörter pro Topic angepasst werden. Wenn Sie die Anzahl der Topics ändern, wird die Berechnung komplett neu gestartet und die gesetzten Topic-Bezeichnungen werden zurückgesetzt.
- Oben rechts können Sie die aktuelle Ansicht im QTT speichern, in die Zwischenablage kopieren oder exportieren.
Topic-Dokument-Matrix
Über Start > Topic-Dokument-Matrix im Ergebnisfenster rufen Sie eine Visualisierung auf, die zeigt, welche Topics bei welchem Dokument dominieren.

Als Grundlage für die Darstellung dienen die berechneten Wahrscheinlichkeiten, dass ein Topic bei einem Dokument vorkommt. Der Wahrscheinlichkeitswert zwischen 0 und 1 wird für die Anzeige mit 100 multipliziert.
Mithilfe der Symbole oberhalb der Darstellung lässt sich die Darstellung anpassen, zum Beispiel wie im Bild zu sehen in eine Heatmap umschalten. Die Funktionen in der Symbolleiste am oberen Rand sind im Detail im Manual-Abschnitt zum Code-Matrix-Browser beschrieben.
Topics speichern
Die Zuordnungen der Wörter zu den Topics und die Wahrscheinlichkeiten der Topics pro Dokument lassen sich wie folgt speichern:
Topics als Diktionär speichern – Es wird ein neues Diktionär in MAXDictio erstellt. Als Kategoriennamen werden die Topic-Bezeichnungen verwendet und die Top-Wörter pro Topic werden als Suchwörter eingetragen. Sie sollten das Diktionär auf Doppelungen von Wörtern prüfen, denn es kommt durchaus vor, dass das gleiche Wort für verschiedene Topics bedeutsam ist, meist allerdings mit unterschiedlicher Gewichtung.
Topics als Dokumentvariable speichern – Es wird eine neue Dokumentvariable angelegt und für jedes analysierte Dokument die Topic-Bezeichnung eingetragen, deren Wahrscheinlichkeit am höchsten ist. Wenn mehrere Topics gleich wahrscheinlich sind, wird „nicht definiert“ eingetragen.
Topics als Dokumentsets speichern – Es wird pro Topic ein Dokumentset in der „Liste der Dokumente“ angelegt. Jedes Dokument wird dem Topic-Set mit der größten Zugehörigkeitswahrscheinlichkeit zugeordnet.
Topic Modeling für Survey-Antworten
Wenn Sie die Funktion Analyse > Survey-Antworten kategorisieren nutzen, um Ihre Surveyantworten zu codieren, können Sie Topic Modeling direkt aus dem Analysefenster im Menü Start aufrufen.
Bei der Analyse werden nur die aktuell angezeigten Antworten berücksichtigt.
Abschließende Hinweise
- Topic Modeling ist ein rein statistisch arbeitendes Modellierungsverfahren, das keine Bedeutung von Wörtern berücksichtigt. Dementsprechend können die Ergebnisse von subjektiven Erwartungen abweichen.
- MAXQDA verwendet Gensim mit dem Latent Dirichlet Allocation (LDA) Algorithmus für die Bestimmung der Topics. Zur Reproduktion der Ergebnisse in Gensim: MAXQDA verwendet 50 Iterationen und setzt 1 als Random State, um bei gleichem Input stets die gleichen Ergebnisse zu erhalten.