
Qualitative insights at scale – working with MAXQDA Tailwind on Reddit discourses

Elias Michael Jessen
PhD candidate, Charité – Universitätsmedizin Berlin, Institute for Medical Sociology
Research focus: digital mental health, masculinity, discourse analysis
Project partners: krisenchat gGmbH, Techniker Krankenkasse
Intro
In my doctoral research I explore how men talk about mental health in online spaces, focusing on Reddit as a communicative environment that is thematically driven, anonymous, and shaped by community-based visibility metrics such as upvotes and comment threads. These discussions offer valuable insights into how topics like help-seeking, emotional strain or vulnerability are negotiated within male-coded online cultures. The goal of my project is to reconstruct how different user roles, discursive patterns and emotional framings manifest around psychoeducational content and to consider what this means for the development of future prevention strategies in digital contexts.
From a methodological perspective, I started with an extensive preprocessing step. I used Python and GPT-4o to scrape and reformat 18 long Reddit threads into structured documents that resembled focus group transcripts. This allowed me to represent the nested structure of Reddit discussions, including upvote counts and speaker continuity. Preparing the data in this way required a mix of creative and technical problem-solving, but it helped me become deeply familiar with the material and its discursive logic.
The coded documents were then imported into MAXQDA, where I conducted an initial round of deductive and inductive coding. This first phase made it possible to identify relevant categories such as emotional tone, user positions, controversy, irony and role-based interaction patterns. However, I also quickly encountered limitations. The scale of the material made it difficult to analyse all documents comparatively. Autocoding and searching for co-occurrence patterns worked well in smaller sets, but it was time-consuming and hard to maintain analytic consistency across the full sample.
Working with MAXQDA Tailwind
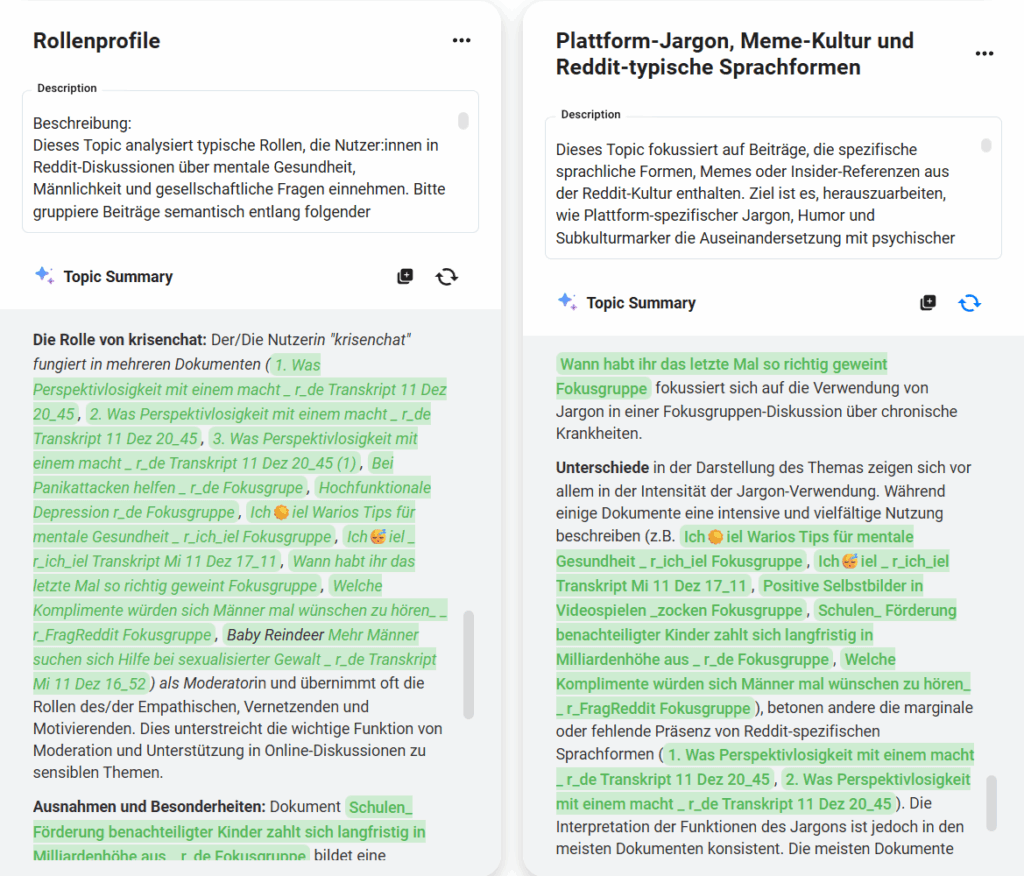
This is where MAXQDA Tailwind came in. Based on the coding structure developed in MAXQDA, I was able to reload all 18 Reddit documents into MAXQDA Tailwind and apply my categories across the dataset in one cohesive run. This made it possible to re-analyse the material using refined, topic-specific coding logic, but now with the benefit of semantic grouping and matrix-based output. The MAXQDA Tailwind chat function turned out to be especially helpful. It allowed me to ask precise questions about discourse dynamics, such as identifying which posts were emotionally supportive and received strong community feedback, or which roles appeared most frequently in controversial threads. I found the language understanding of the model surprisingly nuanced. Reddit-specific expressions, insider jokes and cultural codes such as irony or sarcasm were usually interpreted correctly. I rarely had to rephrase or explain what I was looking for, which speaks to the model’s contextual awareness.

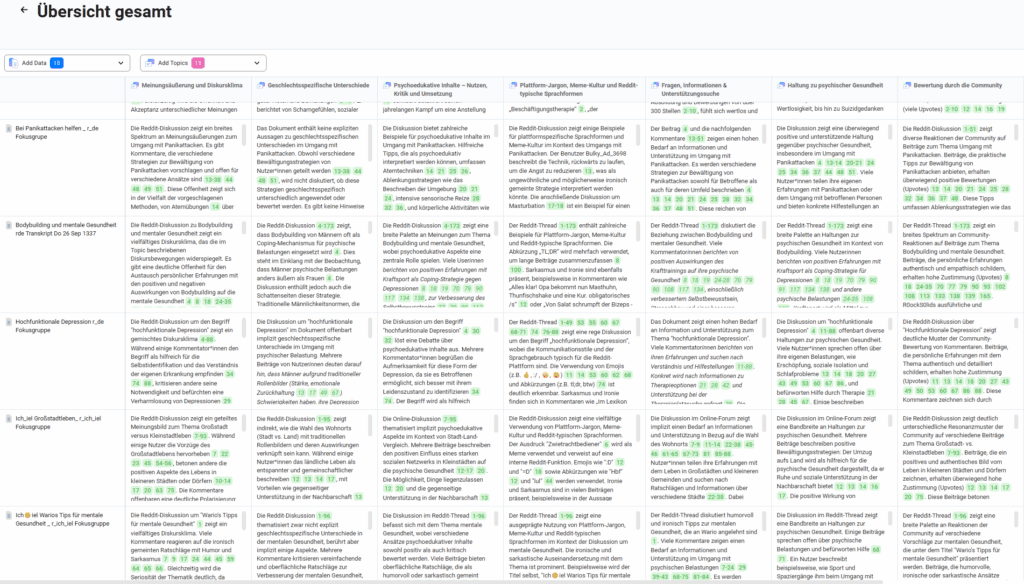
MAXQDA Tailwind offered a significant shift in workflow. It made it possible to move from detailed close reading to comparative analysis across documents without losing interpretative depth. It also encouraged me to rethink how I define categories and formulate analytical questions. The Matrix view was particularly helpful for this, as it provided a clear overview of how certain codes appeared across documents and in which intensity. For example, I was able to trace how emotional openness was expressed differently depending on topic, language style and role profile, or how certain types of comments systematically attracted upvotes or were dismissed by the community. This level of comparative insight would have taken considerably more time and effort in a purely manual process.
Looking ahead, I see great potential in combining MAXQDA Tailwind’s approach with more advanced features. It would be valuable to include analytic tools that better support comment hierarchies and reply logic, or to compare coded clusters visually along discourse axes such as empathy versus judgement or normativity versus irony. I am also curious to see whether future versions of MAXQDA Tailwind will offer more transparent control over how topics and groupings are formed, as this could further support research transparency and replicability.
From my earlier studies, I know how time-consuming it is to manually code, transcribe and structure large amounts of qualitative data. The tools we have today make it possible to preserve the richness of qualitative insight while increasing comparability and reach. MAXQDA Tailwind is part of this shift. It enables low-threshold entry points for exploratory work but can also be used to support theory-driven, in-depth analysis. It doesn’t replace interpretative work, but it makes it more manageable – especially when the material is complex, large-scale and contextually loaded, as is often the case with digital discourse.